

はじめに
統計を学んでいると、信頼区間の解説で必ずといっていいほど、こんな注意書きに出会いますよね。
「95%信頼区間とは、真の値が95%の確率でその区間に含まれる、という意味ではありません」
読んだとき「そうなのか」と一応は納得する。でも、どこかすっきりしない感覚が残る……そういう経験、ありませんか?
この記事では、その「すっきりしなさ」を丁寧に解体していきます。
結論から言うと、この問いを本当に理解しようとすると、「確率とはそもそも何か」という統計の根幹にある問いに触れることになります。
実は統計学には、確率の意味についてまったく異なる立場をとる二つの流派があります。「頻度論(frequentist)」と「ベイズ統計(Bayesian)」です。私たちが教科書で習う信頼区間は、頻度論の枠組みで作られたものです。
この記事は、信頼区間の基本は知っているけど、正しい解釈がどうも腹落ちしない、という方向けに書いています。
そもそも95%信頼区間って何?、という方はこちらの記事をご覧ください。
95%信頼区間について、触れる図を交えて紹介しています。
まず「よくある誤解」から整理しよう
まず誤解をはっきりさせておきましょう。
❌ よくある誤解:「95%信頼区間の中に母平均(真値)が含まれる確率が95%だ」
この読み方、実はすごく自然なんです。「95%」という数字があって、「信頼」という言葉がある。「95%の確率で信頼できる区間」と読みたくなるのは、ある意味で当然の反応だと思います。
でも、これは統計学的には正確ではありません。なぜかというと、母集団の真値――たとえば「日本人成人男性の平均身長」――は、どこかに固定された一つの値として存在しています。確率的にふらふら変動するものではないんです。
固定された値が「ある区間に含まれるかどうか」は、0か1かのどちらかです。含まれていれば1、含まれていなければ0。そこに確率を割り当てる余地はありません。
これは非常にわかりにくい概念で、過去の論文では研究者でも誤った解釈をしている人が非常に多いということが報告されています。
Hoekstra R, Morey RD, Rouder JN, Wagenmakers EJ (2014). Psychonomic Bulletin & Review, 21, 1157–1164.
心理学分野の研究者120名・学生442名を対象に、信頼区間に関する6つの命題(すべて誤り)を「正しいか間違いか」判断させる調査です。結果として、研究者・学生ともに平均3つ以上の命題を「正しい」と判断してしまいました。
特に衝撃的だったのは、統計の経験年数と正答率がまったく相関しなかったこと、そして研究者と「統計を一切習ったことのない学生」の成績がほぼ同レベルだったことです。「95%信頼区間が真値を含む確率は95%だ」という解釈が最も多く支持された誤りでした。
著者たちはこれを「robust(頑健な)誤解」と表現しています。直感的に自然に見えるがゆえに、経験を積んでも修正されにくい、という意味です。
✅ 正しい解釈:「同じ手順でデータ収集と区間推定を繰り返すと、そうして得られた区間のうち95%が真値を含む」
少し回りくどいですよね。「確率」ではなく「割合(頻度)」の話なんです。動いているのは真値ではなく、信頼区間の方です。
標本を取り直すたびに、計算される信頼区間は変わります。ある回の区間は真値を含み、別の回の区間は含まない。その長期的な割合が95%になる――これが信頼区間の正確な定義です。
信頼区間は、個々の推定結果に何かを保証するのではなく、「推定の手順(アルゴリズム)の性能」を表しているわけです。
「期待値0.95 = 確率0.95」ではないの?
ここで一つ、鋭い疑問が出てくることがあります。
仮に、真値を含む信頼区間を1、含まない信頼区間を0とする指標を考えてみます。無限回の試行で得られた無限個の信頼区間について、この指標の期待値は0.95になります。
そして実際の分析では、その無限個の信頼区間の中からたまたま一つが手元に届いている。「無限回の中からランダムに1つ引いた」とみなせるなら、手元の区間が真値を含む確率は0.95では?
この論理、実はほぼ正しいんです。でも――
頻度論の立場では、最後の一歩が許されない。
なぜかを、次の節で説明します。
「観測前」と「観測後」の非対称性
頻度論における確率は、「繰り返し可能なランダムな仕組みに対して定義される」ものです。
観測「前」の段階では、どの区間が得られるかはランダムです。このとき確率を使うことは正当化されます。
でも、一度データを取得して具体的な区間 [a, b] が手元に現れた瞬間、その区間はもはや確率変数ではなく「固定された定数」になります。真値も固定。区間も固定。そこには確率の入り込む余地がなくなってしまうんです。
コイン投げで考えるとわかりやすいです。
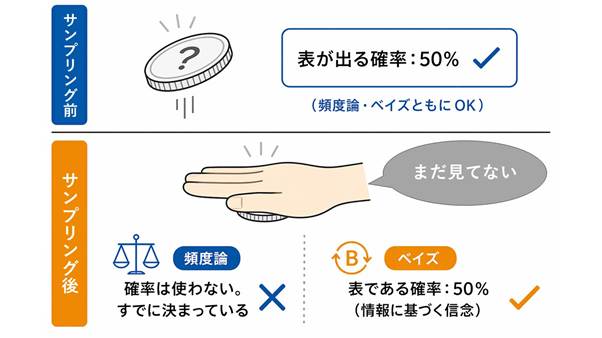
コインを投げる「前」なら、「表が出る確率は0.5」と言えます。ここまではOK。
では、コインをすでに投げて結果が出た後(まだ見ていない状態)はどうか? 頻度論の立場では、「もう結果は決まっているのだから、確率を使う場面ではない」となります。
先ほどの「期待値0.95だから確率0.95では?」という発想は、「事前のランダム性」をそのまま「事後の特定の区間への確率」へ転用しようとするジャンプです。頻度論はそのジャンプを認めない、というわけです。
……正直、これは最初に知ったとき衝撃的です。観測してしまった後は、もう確率をつけられない。直感に反しますよね。でも、これが頻度論の立場の核心部分です。
では、なぜ「病気である確率」は言えるのか?
ここで別の疑問が生まれます。
ある患者が特定の検査で陽性反応を示した。「この患者が実際に病気である確率は何%か」――この問いに対して、医療の場では普通に「確率」を使って答えますよね。
でもよく考えると、この患者が病気かどうかはすでに決まっています。病気か、病気でないか。0か1かです。信頼区間と同じ構造のはずなのに、なぜこちらは確率で答えていいんでしょう?
実は、「何に確率を割り当てているか」と「どの確率の枠組みを使っているか」が違います。
診断確率の文脈で使われているのは「ベイズ統計での確率」です。ベイズの立場では、確率は「長期的な頻度」ではなく、「情報に基づく確信の度合い」を表します。
患者が病気かどうかは決まっている。でも「私たちはまだ知らない」。その「知らない」という状況を数値化したものが診断確率です。検査結果(陽性)という情報が加わることで、その確率が更新される。これがベイズ更新の考え方です。
整理するとこうなります。
| 比較点 | 信頼区間(頻度論) | 診断確率(ベイズ) |
| 真値・状態 | 固定 | 固定 |
| 不確実性の源 | データのばらつき | 観測者の知識の不足 |
| 確率の意味 | 長期的な頻度・割合 | 信念・不確実性の度合い |
| 観測後 | 確率を使わない | むしろここからが本番 |
Luiz Hespanhol,Braz J Phys Ther. 2018 Dec 31;23(4):290–301.
要約
- 信頼区間(CI)は、得られたデータが「どれだけ再現性のあるプロセスで得られたか」を示すものであり、手元のその数値自体が真値を含む確率を語るものではない、と明快に指摘しています。
- 対照的に、ベイズ統計による信用区間(CrI)は、「手元のデータに基づいて、真値がこの範囲にあるとどれくらい確信できるか」を直接的に確率で示せることを解説しています。
- 筆者らは、臨床決定においては「この治療が効く確率は〇%か?」というベイズ的な問いの方が直感に近く、有用な場合が多いことも示唆しています。
リンク PubMed(全文閲覧可能)
頻度論とベイズ――二つの「確率」観
ここで、本質的な対比が見えてきます。
頻度論(frequentist)の確率は、「無限に繰り返し可能な場合を考えたとき、ランダム現象がどのくらいの割合で起きるか」を表します。コインを1万回投げたとき表が出る割合、ある手順で推定した区間のうち真値を含む割合。こういった「世界の中にある客観的なランダム性」に基づいています。
だから頻度論は、一度限りの出来事や固定されたパラメータに対して確率を使うことができません。母平均は固定された値であり、1回の研究でサンプリングして推定された信頼区間も固定されたもので、どちらも動きようがありません。そこには確率は存在せず、含んでいる/含んでいないのどちらかだ、というのが頻度論のスタンスです。そのため、頻度論では「その値が信頼区間に含まれる確率」は定義できないのです。
ベイズ(Bayesian)の確率は、「ある命題についての確信の度合い」を表します。観測者が持っている情報の多さ・少なさが確率に反映され、新しい情報が来るたびに確率(確信の度合い)は更新されます。
だからベイズでは、パラメータそのものに確率分布を与えることができます。「データを見た後、母平均がこの区間に含まれる確率は95%だ」という命題は、ベイズの枠組みでは意味を持ちます。これを信用区間(credible interval)と呼びます。
一言で対比するなら、こうなります。
頻度論の確率:世界の物理的なランダム性に関する客観的な記述
ベイズの確率:観測者の知識・情報の状態に関する主観的な記述
それぞれの統計手法が「95%信じているもの」は何か
ここまでの話を踏まえると、「95%」という数字が指しているものが、頻度論とベイズでまったく異なることがわかります。
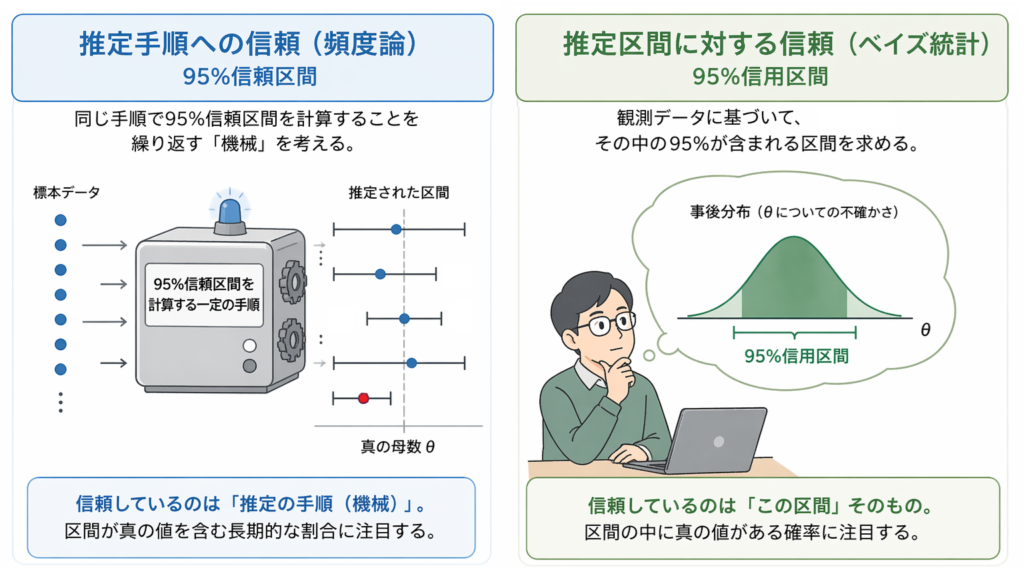
頻度論が95%信じているもの:「この手順の性能」
頻度論は、個々の区間に95%を割り当てません。そうではなく、「この手順で区間を作り続けたとき、95%の区間が真値を含む」という手順そのものの長期的な信頼性を95%と表現しています。
データを取得してそこから信頼区間を推定する機械を想像してみましょう。指示を出せばこの機械はデータ取得と信頼区間推定を何度でもできます。頻度論が信じているのは、この機械が95%の割合で正確な信頼区間を推定することです。機械が推定した個々の信頼区間については何も言っていません。言い換えると、信頼しているのは「機械(仕組み)」であって、機械が今回出した「答え」ではないのです。
ベイズが95%信じているもの:「この区間が真値を含むこと」
ベイズの信用区間は、観測データを見た上で「真値がこの区間に存在する」という命題に対して、95%という確信の度合いを割り当てています。
これは文字通り、「この区間を信じている」ということです。手元の1本の区間に対して、直接95%という数字を対応させています。
この違いを整理するとこうなります。
| 頻度論(信頼区間) | ベイズ(信用区間) | |
| 95%が指すもの | 手順の長期的な性能 | この区間が真値を含む確信度 |
| 信じているもの | 推定の「仕組み」 | 目の前の「区間」 |
| 一つの区間に確率を割り当てるか | 割り当てない | 割り当てる |
多くの人が「95%信頼区間」に期待している読み方――「この区間が真値を含む確率が95%」――は、実はベイズの信用区間が担っている役割です。名前は信頼区間だが、直感が期待しているのは信用区間、というのが混乱の正体かもしれません。
まとめ
「95%信頼区間は真値を含む確率が95%」と言えない理由を整理しましょう。
・母平均(真値)は固定されたパラメータであり、確率的に変動するものではない
・信頼区間は「推定の手順の性能」を表す。動いているのは区間の方
・観測後に固定された区間に対して、頻度論では確率を再割り当てしない
・「期待値0.95だから確率0.95では?」という直感は、事前のランダム性を事後に持ち込むジャンプであり、頻度論ではそれを認めない
そして、「病気である確率」のような診断確率は、別の確率の枠組み(ベイズ)で語られているから「確率」と言えています。
この混乱の根本にあるのは、「確率」という同じ言葉が、二つのまったく異なる概念を指して使われているという事実です。
| 頻度的確率 | ベイズ的確率 | |
| 確率が表すもの | 世界の中の客観的なランダム性 | 観測者が持つ信念・不確実性 |
| 信頼区間で言えること | 手順の性能(割合) | 言えない(信用区間なら言える) |
頻度論の枠組みで定義された信頼区間を、ベイズ的な確率で解釈しようとすると、必ずズレが生じます。「95%の確率で真値を含む」という読み方がしたいなら、信用区間(ベイズ信頼区間)を計算すればいい。それは正当な手続きです。
補足:なぜ頻度論はこの立場をとるのか
最後に少し立ち止まって考えたい問いがあります。なぜ頻度論は「観測後の固定された対象に確率を使わない」という、直感に反するように見える立場をとるのか。
答えは「客観性の担保」にあります。確率を「長期的な頻度」と定義することで、確率は誰が計算しても同じ値になる客観的な量になります。ベイズの「信念の度合い」は、事前確率(prior)の設定によって人によって異なる可能性がある。頻度論はそれを避けようとしました。
どちらが正しいかという問いに対して、統計学者の間でもいまだに議論があります。実際には両方の枠組みが用途に応じて使い分けられています。
「確率とは何か」という問いは、統計の入り口に見えて、実は統計の本質に直結しています。


コメント