

論文を読んでいると必ず出てくる「調整」や「多変量解析」という言葉。これらはすべて、今回解説する**「交絡因子(こうらくいんし)」**という厄介な存在に対処するためにあります。
「この治療法は有効だ!」という結論を鵜呑みにしないための、クリティカル・シンキングの武器を身につけましょう。
交絡因子とは「結果に下駄をはかせる要因」
交絡因子を一言でいうと、**「本来の因果関係をゆがめてしまう、第三の要因」**のことです。
例えば、ある新しい「筋トレサプリ」の効果を調べたとしましょう。
- A群: サプリあり。筋肉量が15%アップ。
- B群: サプリなし。筋肉量が5%アップ。

これだけ見れば「サプリすごい!」となりますよね。しかし、よく背景を見てみると……
- A群: 平均年齢25歳の20名
- B群: 平均年齢55歳の大学生20名
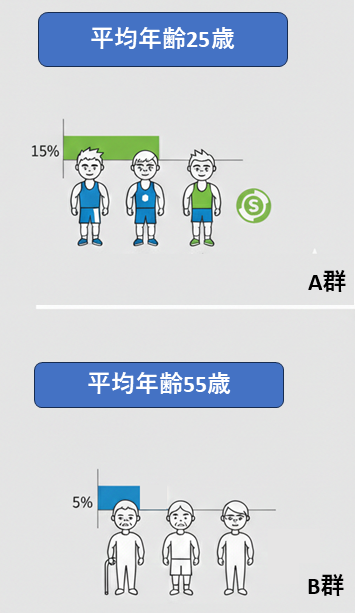
だったとしたらどうでしょうか?
一般に、筋肉は若い人のほうがつきやすいものです。
この場合、筋肉量の差はサプリの効果ではなく、年齢の違いによって生じた可能性があります。
つまり、「筋肉量が増えた原因」が
- サプリなのか
- 年齢なのか
区別できなくなってしまいます。
このとき、年齢が結果に“下駄をはかせた”要因になります。
このように、因果関係の解釈をゆがめてしまう変数を交絡因子と呼びます。(結果を悪いほうに変化させるものも、交絡因子といいます。)
交絡因子と呼ぶための「3つの条件」
では、どんな変数が「交絡因子」になるのでしょうか? 統計学の世界では、以下の3つの条件をすべて満たすものと定義されています。先ほどのサプリの例(年齢)に当てはめて考えてみましょう。
| 条件 | 内容 | サプリの例でいうと? |
| ① 原因と関連がある | その因子が、調べたい原因(曝露)と関係していること。 | 若い人ほど、サプリを熱心に飲む傾向がある。 |
| ② 結果と関連がある | 原因とは無関係に、その因子単独でも結果に影響を与えること。 | サプリを飲まなくても、若いほうが筋肉はつきやすい。 |
| ③ 中間点ではない | 「原因 → 因子 → 結果」という、一本道のルート(中間点)ではないこと。 | 「サプリを飲む → 食欲が増す → 筋肉が増える」の場合、食欲は交絡ではなく「メカニズム」の一部です。 |
この3つが揃ったとき、その変数は「黒幕(交絡因子)」として、私たちの目をくらませにやってきます。特に**③の「中間点ではない」**という視点は非常に重要です。ここを見誤ると、せっかくのサプリの効果を統計解析の結果から消し去ってしまうことになりかねません。
交絡因子と「共変量」の違い
よく似た言葉に「共変量(きょうへんりょう)」があります。
- 交絡因子: 「結果をゆがめる要因」という、概念的な呼び方。
- 共変量: 統計ソフトで計算する際に、モデルに投入する変数としての呼び方。
料理に例えるなら、「隠し味(交絡因子)」を突き止めて、実際に鍋に「調味料(共変量)」として投入する、というイメージです。
「見えない交絡」が一番怖い
交絡因子には2種類あります。
- 既知の交絡因子: 年齢、性別、既往歴など。データとして測定できるもの。
- 未知の交絡因子: 遺伝子の違い、性格、家庭環境など。データとして取っていない(取れない)もの。
重回帰分析などの統計手法で「調整」できるのは、あくまで**「1. 既知の交絡」だけです。 どれだけ高度な統計を駆使しても、データにない「2. 未知の交絡」は取り除けません。これを一気に解決できる唯一の方法が、被験者をくじ引きで分ける「ランダム化比較試験(RCT)」**なのです。
交絡因子をどう見つけるか?(DAGの活用)
交絡因子は、統計ソフトが自動で見つけてくれるものではありません。以下のようなステップを踏んで、交絡因子を特定していくのがおすすめです。
① 先行文献と専門知識(エビデンスの収集)
まずは、統計の計算を始める前に「何が結果に影響を与えそうか」の情報を集めます。
- 先行文献にあたる: 過去の研究でどの変数が調整されているかを確認します。
- 生理学的メカニズムから考える: 体の仕組みからして関係がありそうな数値をリストアップします。
- ドメイン知識(現場の感覚): 現場を知る人間だからこそ気づける「生活背景」などの要因を考えます。
② 因果関係を「交通整理」する
候補が出揃ったら、それらの関係性を整理します。最近の論文では、因果関係を矢印で結んだ**DAG(有向非巡回グラフ)**という図を使って、論理的に分析することが増えてきています。

例えば、**「筋力トレーニングの負荷量」が「筋肉量」**に与える影響を調べたいとします。
このとき、上図のように**「年齢」**という変数を考えてみましょう。
- 年齢は、トレーニングの負荷量に影響します(若い人ほど高負荷でやりやすい)。
- 同時に、年齢は筋肉量そのものにも影響します(加齢とともに筋肉は減りやすい)。
このように、原因と結果の両方に足を突っ込んでいる「年齢」のような因子が交絡因子です。この図(DAG)を見れば、「年齢の影響を固定(調整)しないと、トレーニングの純粋な効果が見えない」ということが一目でわかります。
また、矢印のつながり方によっては、調整するとあるはずの効果を消してしまう場合もあります。
このように、「どの変数を統計モデルに入れるべきか(あるいは入れるべきでないか)」を交通整理するための地図がDAGなのです。
[コラム] 「有意差が出たから入れる」はNG?
昔は「統計的に関連がありそうなものを片っ端から入れる」という手法(ステップワイズ法など)も使われていましたが、現在では推奨されません。
なぜなら、理論に基づかない調整は、逆に結果をゆがめるリスクがあるからです。**「何を入れるかは、計算の前に人間が(理論的に)決める」**のが鉄則です。
交絡因子を「防ぐ・取り除く」ための方法
研究の信頼性を高めるために、研究者はさまざまな方法で交絡因子を取り除く努力をしています。
研究デザインで防ぐ(予防)
データを取り始める前の段階で交絡をシャットアウトする方法です。
- ランダム化: 患者さんをくじ引きで分ける。これにより、年齢などの「既知の因子」だけでなく、性格や遺伝子といった「未知の因子」まで均等に分けることができます。
- 盲検化(ブラインド): 誰がどの治療を受けているか隠すことで、期待感やプラセボ効果という交絡を防ぎます。
統計手法で取り除く(後片付け)
統計処理により出てしまったデータの偏りを、計算で修正する方法です。先行文献やメカニズムから考えられる交絡因子をDAGで整理したら、調整が必要な因子を統計モデル入れて分析します。
代表的な方法として以下のような統計手法があります。
- 重回帰分析(多変量解析)
「年齢」などの共変量をモデルに入れ、その影響を差し引いて計算します。 - 共分散分析(ANCOVA)
群(介入群・対照群など)による差を比較しつつ、年齢などの連続変数の影響を統計的に調整します。「群の効果」と「共変量の影響」を同時に評価できる方法です。 - 傾向スコアマッチング
背景が似た者同士(例:50代・男性・既往歴あり)をペアにして比較します。
論文を読む時のチェックリスト
今後、抄読会などで論文を読むときは、以下の3点をチェックしてみてください。
- 背景に偏りはないか?(Table 1を見る): A群とB群で、年齢や重症度が大きく違わないか確認しましょう。
- その因子は調整されているか?: 「多変量解析」の項目を見て、自分が怪しいと思った因子(年齢など)が計算に入れられているか確認します。
- 研究デザインは適切か?: 観察研究(調整が難しい)なのか、RCT(未知の交絡まで排除できている)なのかを確認しましょう。
まとめ
統計解析の目的は、データのノイズを払い落とし、**「純粋な因果関係」**を浮き彫りにすることです。最後に、今回の重要ポイントを振り返りましょう。
- 交絡因子は「第三の黒幕」 原因と結果の両方に影響を与え、結論をゆがめてしまう要因です。「サプリで筋肉が増えたのか、単に若かったからか?」と疑う姿勢が大切です。
- 「既知の交絡」と「未知の交絡」 データとして取れるもの(年齢など)は統計で調整できますが、取れないもの(遺伝子や性格など)は**RCT(ランダム化比較試験)**でしか解決できません。
- 調整は「理論」が先、「計算」は後 「統計的に有意だから」と何でも調整するのは危険です。先行文献や生理学的メカニズムに基づき、**DAG(因果構造図)**などを使って「何を調整すべきか」を人間が判断する必要があります。
- 論文を読むときは「Table 1」から まずは群間の背景に偏りがないかを確認しましょう。もし偏りがあれば、その項目が多変量解析で正しく「調整」されているかをチェックするのが、正しい論文の読み方です。
交絡因子の存在を知ることは、情報の「裏側」を読む力になります。次に論文を手に取るときは、ぜひ「ここにはどんな交絡が隠れているかな?」と探してみてください。
交絡因子に関連する記事
JASPでサクッと重回帰分析
JASPでサクッと共分散分析
JASPでサクッとロジスティック回帰分析
検出力(検定力)とは?
多重比較とは?

【著者について】
理学療法士(回復期リハビリ病棟 12年以上)
統計検定2級・Python 3エンジニア認定(データ分析)取得。
臨床現場でのデータ活用を目的に統計・機械学習を独学。
FIM退院予測モデルを個人で設計・実装(スタッキングアンサンブル+SHAP)。
強化学習(MuJoCo/Walker2d)や高位頸髄損傷患者向けデバイスの
自作など、臨床課題を技術で解くことに関心を持つ。
医療職向けに統計・データサイエンスをわかりやすく解説するブログ
「Curiosity Creates」を運営中。


コメント