

機械学習やディープラーニングを利用した予測モデルの利用が一般的になってきています。売り上げ予測や在庫管理など、将来が高精度に予測できると良い場面はたくさんあります。
医療分野でも、近年は予測モデルを活用する場面が増えてきました。学会やジャーナルでも様々な予測モデルが発表されており、それらには必ずといっていいほど「モデルの性能」を表す数値指標が記載されています。
しかし、いざ評価指標を見てみると、表示される指標がたくさんあって「何が何やら……」となることも多いでしょう。この記事では、回帰モデルの評価指標を中心に、
- 各評価指標の意味
- どんな場面で使うと良いか
について解説します。
なお、分類モデルの評価指標については、こちらの記事で紹介しています。
回帰モデルの評価指標
回帰モデルの評価指標には様々な物があります。まずは、良く使用されるものを中心に、どのような指標があるのかご紹介します。
MAE(Mean Absolute Error:平均絶対誤差)
- 定義:予測値と実測値の差の絶対値の平均。
- 特徴:外れ値に対して比較的鈍感で、誤差をフラットに評価。数値が低いほどいい。
- 実務での使い所:単純な「どれくらいズレたか」を知りたいとき。例:医療現場での予後予測など。
MSE(Mean Squared Error:平均二乗誤差)
- 定義:誤差の2乗の平均。
- 特徴:大きな誤差(外れ値)を強く評価。数値が低いほどいい。
- 実務での使い所:損失関数としてよく使われる。モデル学習時の勾配計算に適している。
RMSE(Root Mean Squared Error:平方根平均二乗誤差)
- 定義:MSEの平方根。
- 特徴:MSEと同様に大きな誤差を重視するが、単位が元のデータと同じになるため解釈しやすい。数値が低いほどいい。
- 実務での使い所:医療や工学など、実測値と単位を合わせたい分野で有用。
MAPE(Mean Absolute Percentage Error:平均絶対パーセント誤差)
- 定義:誤差を実測値で割ったパーセンテージの平均。
- 特徴:直感的にわかりやすく、0〜100%で評価できる。数値が低いほどいい。
- 注意点:実測値が0に近い場合、計算不能や誤差増大の可能性あり。
- 実務での使い所:売上や収益など、相対的な誤差が重要な経済分野。
R²(決定係数)
- 定義:モデルがデータのばらつきをどれだけ説明できているか(0〜1の範囲)。
- 特徴:回帰モデル全体の説明力を測る指標。高いほどいい。
- 注意点:非線形モデルでは誤解を招く場合がある。
- 実務での使い所:重回帰分析など、線形モデルの評価時。
Adjusted R²(自由度調整済み決定係数)
- 定義:説明変数が増えたときにR²が機械的に上がる問題を補正した指標。
- 実務での使い所:説明変数が多い線形モデルを比較する際に重要。
MSEとMAEで評価が変わる例
以下の図では、人工的に生成したデータに対して安定型・ムラありモデルという2つの異なるモデルを適用し、それぞれの誤差指標(MSEとMAE)がどう評価を分けるかを比較しています。
- 安定型モデル:予測は常にそこそこ当たっているが、ピタリとは当たらない
- ムラありモデル:多くは当たっているが、たまに大きく外れる
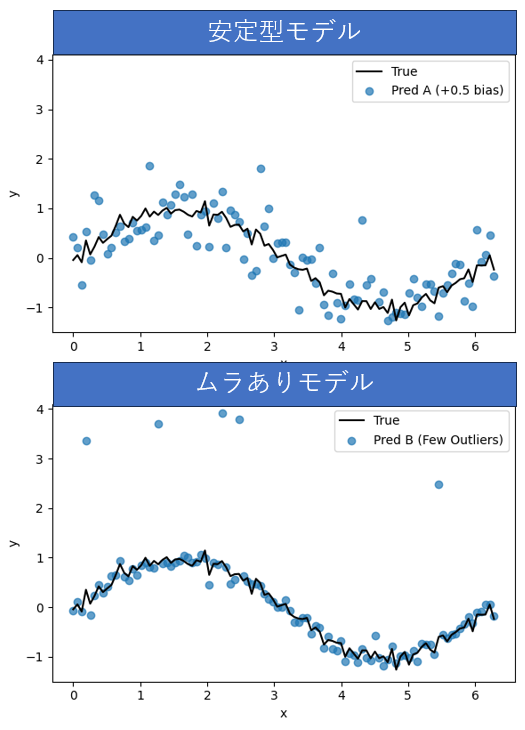
黒の実線が予測すべき真の値(正解データ)で、青い点がモデルの予測値です。青い点が黒線に近いほど、精度の高い予測ができていることを意味します。
安定型モデルではばらつきはありますが、黒線から大きく外れている予測はありません。 ムラありモデルではほとんどの点が黒線にピッタリ沿っていますが、5点ほど極端に外れた予測が存在します。
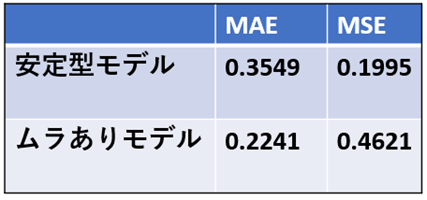
下の表を見てみましょう。MAEとMSEのスコアを見ると、評価の逆転が起きていることがわかります。
- 安定型モデルはすべての予測が多少ズレているため、誤差の平均をとる MAE の評価はあまり良くありません。 しかし、大外しがないため、外れ値に敏感な MSE は良好な値になります。
- 一方、ムラありモデルはほとんどの予測が正確なため 誤差の平均をとるMAE のスコアは良好です。 ただし、数点の大きな誤差が 外れ値に敏感なMSE を悪化させています。
このように、MSEは外れ値に敏感であり、MAEは全体のズレをフラットに評価する指標であることがわかります。この特性を考慮すると、以下のように使い分けるとよいでしょう:
- MSE:全体的な精度はある程度でよいが、「大きく外すこと」は許容できない場合に有効
- MAE:多少大きく外れる予測があってもよいが、ベースラインの予測精度を高く保ちたい場合に有効
実務での評価指標の使い分け例
一般的な予測モデル
- 目的:来店客数予測や長期保管が可能な商品の在庫予測
- 適した指標
- MAE:単純な誤差の平均であり直感的で単位も分かりやすい
医療データでの応用例
- 目的:患者の退院時FIM、10年後eGFRなどの予測
- 適した指標:
- MSE:モデルが症例の予後を予測する時、大きく外すことが無いか確認しやすい
- RMSE:大きな外れ値を重視しつつ、単位も保てる
売上・収益予測
- 目的:来月の売上、年間利益率などの予測
- 適した指標:
- MAPE:パーセンテージでの誤差が重要になる場面で有効
機械学習の学習時
- 目的:モデルの最適化(損失関数)
- 適した指標:
- MSE:微分可能かつ勾配がなめらかなので学習に向いている
残差分析(Residual Analysis)
残差とは、「実測値 − 予測値」の差のことです。残差の傾向を可視化することで、モデルがどのような誤差を生み出しているかを把握できます。
通常、残差プロットでは 横軸に予測値や実測値を取り、縦軸に残差をプロットします。また、特定の特徴量を横軸にとることで、「その特徴量と誤差の関係性」を調べることもあります。
残差プロットを使うことで次のようなことがわかります:
- 残差に偏りやパターンがある → モデルが捉えきれていない非線形性の可能性
- 特定の領域にだけ誤差が集中 → モデルが一部のデータ特性を表現しきれていない
実際の残差プロットは以下のようになります:
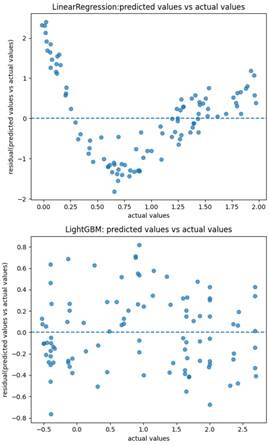
上のグラフは、非線形データに対して線形回帰モデルを適用したときの残差プロットです。残差に曲線的なパターンが見られ、モデルがデータの構造を捉えきれていないことがわかります。
一方、下のグラフは 非線形性に強いLightGBMを使用した例で、残差が均等にばらついています。これは、モデルがさまざまなパターンを比較的適切に学習できていることを示します。
また、グラフの右側(大きな実測値)と左側(小さな実測値)でばらつきの大きさが異なる場合は、特定の領域でモデル精度が低い可能性があります。
たとえば「高齢者のみに影響する交互作用項が抜けている」といった可能性もあるため、そのような場合は特徴量の見直しや追加を検討すると良いでしょう。
まとめ
回帰モデルの性能を評価するためには、複数の評価指標を使い分けることが重要です。
それぞれの指標には特徴があり、「どんな誤差を重視するか」によって使い方が異なります。
- MAE:誤差の平均をフラットに評価。ズレの大きさを直感的に把握したいときに有効。
- MSE/RMSE:大きな外れ値を重視したいときに有効。学習時の損失関数としても多用される。
- MAPE:誤差をパーセンテージで捉えたい場合に便利。売上や経済データの分析に向いている。
- R²/Adjusted R²:モデル全体の説明力を把握する指標。とくに線形モデルではよく使われる。
加えて、残差分析を行うことで、モデルが特定のパターンを見逃していないか、非線形性を捉えられているかなど、数値では見えにくい点も可視化できます。 今後は分類モデルの評価指標(例:感度・特異度、AUCなど)や、モデルの良し悪しを考えるときにチェックすべきその他の項目についても紹介予定です。
分類モデルの評価指標にも興味がある方は、こちらの記事をご覧ください。
ちなみに、実はこうした評価指標だけでは、十分にモデルの評価をする事は出来ません。特に「自分のいる組織や部署にとっての善し悪し」を判断するにはこのほかの点にも目を配る必要があります。
こちらの記事では、評価指標に表れないモデルの善し悪しについてのチェックポイントを紹介しています。興味のある方は併せてごらんください。
回帰モデル評価指標に関連のある記事
線形・非線形の違い
分類モデルの評価指標|Accuracy・Recall・ROC・AUC
過学習とは?
ディープラーニングと回帰分析。何が違う?(線形データと非線形データで比較)
LightGBMと回帰分析(サンプル数毎の比較)
ランダムフォレストと回帰分析の比較


コメント