

この記事のテーマ
以前の記事はディープラーニングと機械学習の一つである回帰分析の精度の違いについて紹介しました。ディープラーニングと回帰分析だと条件によって精度に大きな差が出ていました。
しかし、実のところエクセルで処理するような表データを扱う限り、LightGBMのような高度な機械学習手法ならディープラーニングと比べても絶対的な差は出ないことがほとんどです。
では何が違うのか?
そこで今回は、ディープラーニングとそれ以外の機械学習(=従来の機械学習)との実用上の違いについてご紹介します。
機械学習の分類について
機械学習とは、コンピューターがデータから特徴やパターンなどを自動的に学習する手法を言います。
機械学習と聞くと、「人工知能」や「ディープラーニング(深層学習)」を思い浮かべる方も多いと思います。でも実際には、機械学習という枠の中には様々な手法(LightGBM、SVM、主成分分析・・・等)があり、その中の一つがディープラーニングです。ディープラーニングは、数ある機械学習手法の中の一つにすぎません。
ディープラーニングに対して、それ以外の一般的な機械学習手法は「従来の機械学習」や「浅い学習(Shallow Learning)」と呼ばれることもあります。上で挙げたLightGBM、SVM、主成分分析などがここに含まれます。
一口に機械学習といっても、手法の幅はかなり広く、シンプルな回帰分析から、チューニングが必要な高度なモデルまで多種多様です。
同じ「分類」や「回帰」もできる
まず最初に知っておきたいのは、ディープラーニングも、それ以外の機械学習も、分類や回帰といった基本的なタスクにどちらも使えるということです。
たとえば、住宅価格の予測(回帰)や、メールがスパムかどうかの判定(分類)など、どちらの手法でもこなせます。実際、多くの機械学習プロジェクトでは、LightGBMやランダムフォレストのような「従来の機械学習(Traditional Machine Learning)」が活躍しています。
テーブルデータでは決定的な差はない
Excelのような表形式のデータ(テーブルデータ)を扱う限りでは、「ディープラーニングでなければできない!」という決定的な差はほとんど見られません。
もちろん、計算時間や精度、チューニングのしやすさなどには差があるため、用途に応じて選ぶ必要があります。ただし、業務上の多くのケースでは、LightGBMやXGBoostのような従来型モデルの方が、学習が速く、精度も十分ということが少なくありません。
では何を扱う時に決定的な差が出るか?
決定的な違いは、画像や動画・音声などの「非構造化データ」を扱うときに現れます。(※非構造化データとは、表形式にまとまっていないデータのことです)
画像や動画・音声といった「非構造化データ」を扱う場合には、ディープラーニングの真価が発揮されます。この分野において、従来の機械学習とは決定的な差があります。
具体的には、以下の2点がポイントです。
① 特徴量を自動で抽出できる
従来の機械学習では、モデルに与える「特徴量(= どんな情報を使って予測するか)」を人間が考えて作らなければなりません。
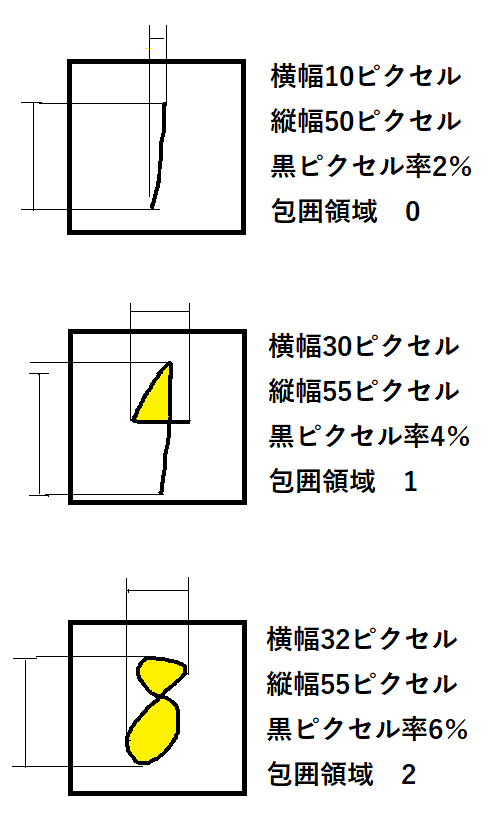
たとえば、手書きの数字を判別したい場合:
- 従来の機械学習:
→ 画像から「黒いピクセルの数」「黒い領域の最大横幅」「囲まれた空白があるか」など、判別に役に立ちそうな特徴を人間が考え出して数値化する必要があります。具体的には下のような具合です。(この手順を特徴量エンジニアリングと言います)
モデルの最終的な性能は、モデルそのものの特性のほかに、特徴量エンジニアリングの良し悪しにも影響されました。
- ディープラーニング:
→ 画像データをそのまま入力すれば、ニューラルネットワークが自動で特徴を抽出します。人間では気づかない微妙な違いまで捉えることができます。
この「特徴量エンジニアリングの自動化」は、ディープラーニング最大の武器のひとつです。
医療現場でも、この利点は非常に大きな意味を持ちます。
たとえば、胸部X線画像における正常な肺野と、すりガラス影のような微妙な異常の違いを、従来の機械学習モデルに判別させようとすると、人間が特徴量(濃度、形状、位置など)を定義して与える必要があり、その作業は極めて困難です。
一方でディープラーニングは、画像全体を入力するだけで、人間では見落とすようなパターンや特徴を自動で抽出してくれます。
実際に、顔の血管の微細な血流変化をもとに、非接触で血圧を推定するようなモデルも開発されており、ディープラーニングならではの強みが活かされています。
② 学習済みモデルを別のタスクに再利用できる(転移学習)
ディープラーニングでは、すでに学習済みのモデルの一部(とくに画像の基本的な輪郭や色を捉える「下層」の部分)を、別のタスクに使い回すことができます。
たとえば:
- 「猫とトラを見分けるモデル」を学習したニューラルネットワークの下層は、哺乳類の輪郭や毛の特徴を捉えています。
- これを「チワワとオオカミを見分けるモデル」に転用すれば、再学習に必要なデータや時間を大きく削減できます。
この「転移学習(Transfer Learning)」の考え方は、少ないデータで高精度なモデルを作るための重要なテクニックとして活用されています。医療分野では学習用の教師データの量が限られることが一般的です。医療分野での例としては肺炎診断用に学習させたモデルの下層部分を流用して結核診断モデルを作成する、などが考えられます。
まとめ:ケースに応じて「ちょうどいい」手法を選ぼう
| 特徴 | 従来の機械学習 | ディープラーニング |
| 回帰・分類の基本タスク | ◎ | ◎ |
| 特徴量の設計 | 人間が行う | 自動で抽出 |
| 非構造化データへの強さ | △ | ◎ |
| テーブルデータへの適用 | ◎ | ◎ |
| 転移学習の活用 | △ | ◎ |
最終的には、「どちらが優れているか」ではなく、**「用途に応じて最適な手法を選ぶ」**ことが重要です。
扱うのが表形式のデータなら、まずは従来の機械学習を試すのがセオリーですし、画像や音声を扱うのであれば、ディープラーニングの出番です。
おわりに
ディープラーニングは確かにパワフルですが、魔法のツールではありません。従来の手法にもまだまだ活躍の場があり、特にビジネスの現場では「地味にすごい」従来型のモデルが支えていることも多いです。
この記事が、ディープラーニングとその他の機械学習をうまく使い分けるヒントになれば嬉しいです!

【著者について】
理学療法士(回復期リハビリ病棟 12年以上)
統計検定2級・Python 3エンジニア認定(データ分析)取得。
臨床現場でのデータ活用を目的に統計・機械学習を独学。
FIM退院予測モデルを個人で設計・実装(スタッキングアンサンブル+SHAP)。
強化学習(MuJoCo/Walker2d)や高位頸髄損傷患者向けデバイスの
自作など、臨床課題を技術で解くことに関心を持つ。
医療職向けに統計・データサイエンスをわかりやすく解説するブログ
「Curiosity Creates」を運営中。


コメント