

背景:せっかく作ったモデル、誰が使うの?
データサイエンスや機械学習のモデルを作ったはいいけど、こんな状況になったりします。
「このモデル、Pythonが使える人しか動かせなくない?」
頑張って集めたデータを前処理して、ディープラーニングで学習させて……と苦労して作った予測モデルも、Pythonが使えない人にはただの .h5 ファイルや .pkl ファイルにしか見えません。
自分が関わっている リハビリ現場や研究分野では、「プログラミングは分からないけれど予測モデルは使ってみたい」というニーズがありました。そんな中で、「誰でも簡単に使えるディープラーニングアプリを作ってみよう」と思い立ったのが今回の取り組みのきっかけです。
目指したアプリ:tkinterで最低限のGUIを作る
Python標準のGUIライブラリ tkinter を使って、以下の機能をもった簡単なアプリを作成しました。
実装した機能(v1.0)
- 学習データ(CSV)の読み込み
- ニューラルネットワークの学習(中間層2層・各16ユニット・活性化関数ReLU)
- 学習済みモデルの保存
- 保存済みモデルを使って予測 → 結果をCSVで出力
TensorFlow/Kerasを用いて、.h5形式でモデル保存・読み込みを行います。学習済みのパラメーターは、いつでも再利用可能なので、1回学習しておけば何度でも予測に使えます。
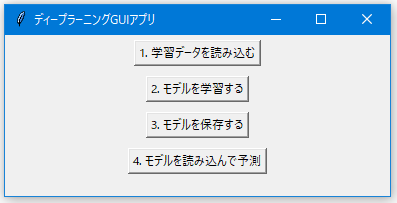
メニューは以下のようなものにしました。それぞれのボタンを押すとダイアログが開いてファイルを選べます。読み込んだファイルのfim_outをfim_in,age,mmse,paralysis の4つの変数から予測するモデルを作成します。
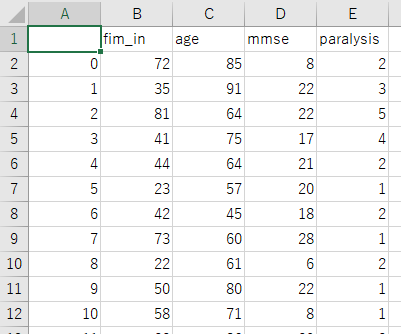
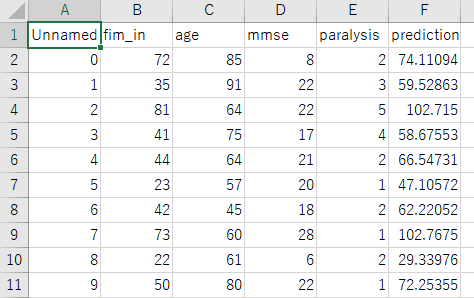
学習データでディープラーニングモデルの学習後に、予測したいデータを読み込ませます。予測を実行すると以下のように「prediction」列が追加された新しいファイルが保存されます。
今回は機能をシンプルに絞りましたが、学習曲線の可視化や予測精度の出力などを追加するのも、少し手を加えれば出来そうです。
ハマったポイント:scikit-learnがexeに入らない!
アプリが完成したら、次はPythonをインストールしていない環境でも使えるように .exe ファイル化します。ここで使用したのが PyInstaller。
ここでちょっとしたトラブルがありました。
pyinstaller --onefile gui_deep_learning.py
このように一発で作れればよかったのですが、scikit-learn のモジュールが exe に含まれないというエラーに直面。
通常pyinstallerというライブラリは、コードに含まれているライブラリを検出して自動的にexeファイルに組み込んでくれます。
今回のコードは以下の部分でsklearnのライブラリをインポートすることを記載していました。from sklearn.model_selection import train_test_split
しかし、今回のケースではPyInstallerはそれをうまく検出できなかったようです。
回避策
最終的には、以下のように --hidden-import=sklearn
bashコピーする編集するpyinstaller --onefile --hidden-import=sklearn gui_deep_learning.py
しかし、これだとscikit-learnの全ライブラリが含まれてしまい、生成された exe のサイズはまさかの 300MB超え。exeファイルのダブルクリックから使用可能になるまで10秒以上かかります。
今思えば、以下のように実際に使っているモジュールだけを指定すればよかったのかもしれません
--hidden-import=sklearn.model_selection
--hidden-import=sklearn.preprocessing
今後の改善点
今回のアプリは「最小構成」にしたため、使い勝手はまだまだです。今後追加したい機能としては:
- CSVファイルの列名から予測対象を選べる機能
- ディープラーニング、lightGBM、ランダムフォレストなどモデルの切り替え
- ハイパーパラメーターの指定
- 学習曲線や精度レポートの出力(MSE, R²など)
また、.exe のサイズ削減のためには、使うライブラリをもっと厳選して --hidden-import を細かく指定する必要があると感じました。
まとめ
- Pythonが使えない人でもディープラーニングモデルを使えるよう、マウスクリックで使えるGUIアプリを作成した。予測モデルのアプリも作ってみれば意外と作れる。
- ちょっとしたトラブルはあったが回避可能で、大きな問題にはならなかった。ライブラリがexeファイルに入らなかったら明示的に指定してみる。
- exeファイルに組み込むライブラリは選ばないと動作が重くなる。実用性は今後上げていく。
おわりに
今回の取り組みは、「作って終わり」ではなく、「誰でも使える予測モデルをどう届けるか?」という視点を持つきっかけにもなりました。
リハビリや教育の現場では、「データサイエンス × 現場の知見」が合わさることで初めて意味のある価値が生まれます。今後もこうした実用的で“使える”ツールを模索していきたいと思っています。
今回exe化したコード
Python3.9.13
pandas version: 2.2.3
numpy version: 1.25.2
scikit-learn version: 1.4.2
tensorflow version: 2.15.0
上記のバージョンでVS Codeで作成しています。
import tkinter as tk
from tkinter import filedialog, messagebox
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from tensorflow.keras.models import Sequential, load_model
from tensorflow.keras.layers import Dense
class DLApp:
def __init__(self, master):
self.master = master
master.title("ディープラーニングGUIアプリ")
# ボタンの作成
self.load_data_btn = tk.Button(master, text="1. 学習データを読み込む", command=self.load_data)
self.train_btn = tk.Button(master, text="2. モデルを学習する", command=self.train_model)
self.save_btn = tk.Button(master, text="3. モデルを保存する", command=self.save_model)
self.predict_btn = tk.Button(master, text="4. モデルを読み込んで予測", command=self.predict_with_model)
self.load_data_btn.pack(pady=5)
self.train_btn.pack(pady=5)
self.save_btn.pack(pady=5)
self.predict_btn.pack(pady=5)
# モデル・データの初期化
self.model = None
self.X_train = self.y_train = None
def load_data(self):
filepath = filedialog.askopenfilename(filetypes=[("CSV files", "*.csv")])
if not filepath:
return
try:
df = pd.read_csv(filepath)
self.X_train = df[["fim_in", "age", "mmse"]].values
self.y_train = df["fim_out"].values
messagebox.showinfo("成功", f"{filepath} を読み込みました。")
except Exception as e:
messagebox.showerror("エラー", f"読み込み失敗: {e}")
def train_model(self):
if self.X_train is None or self.y_train is None:
messagebox.showwarning("警告", "先にデータを読み込んでください。")
return
self.model = Sequential([
Dense(16, activation='relu', input_shape=(3,)),
Dense(16, activation='relu'),
Dense(1)
])
self.model.compile(optimizer='adam', loss='mse')
self.model.fit(self.X_train, self.y_train, epochs=50, batch_size=16, verbose=0)
messagebox.showinfo("完了", "モデルの学習が完了しました。")
def save_model(self):
if self.model is None:
messagebox.showwarning("警告", "学習済みモデルがありません。")
return
filepath = filedialog.asksaveasfilename(defaultextension=".h5", filetypes=[("H5 files", "*.h5")])
if not filepath:
return
self.model.save(filepath)
messagebox.showinfo("成功", f"モデルを {filepath} に保存しました。")
def predict_with_model(self):
model_path = filedialog.askopenfilename(filetypes=[("H5 files", "*.h5")])
if not model_path:
return
try:
model = load_model(model_path)
except Exception as e:
messagebox.showerror("エラー", f"モデル読み込み失敗: {e}")
return
test_csv_path = filedialog.askopenfilename(filetypes=[("CSV files", "*.csv")])
if not test_csv_path:
return
try:
df = pd.read_csv(test_csv_path)
X_test = df[["fim_in", "age", "mmse"]].values
preds = model.predict(X_test)
df["prediction"] = preds
save_path = filedialog.asksaveasfilename(defaultextension=".csv", filetypes=[("CSV files", "*.csv")])
if save_path:
df.to_csv(save_path, index=False)
messagebox.showinfo("成功", f"予測結果を {save_path} に保存しました。")
except Exception as e:
messagebox.showerror("エラー", f"予測失敗: {e}")
# アプリの起動
if __name__ == "__main__":
root = tk.Tk()
app = DLApp(root)
root.mainloop()

【著者について】
理学療法士(回復期リハビリ病棟 12年以上)
統計検定2級・Python 3エンジニア認定(データ分析)取得。
臨床現場でのデータ活用を目的に統計・機械学習を独学。
FIM退院予測モデルを個人で設計・実装(スタッキングアンサンブル+SHAP)。
強化学習(MuJoCo/Walker2d)や高位頸髄損傷患者向けデバイスの
自作など、臨床課題を技術で解くことに関心を持つ。
医療職向けに統計・データサイエンスをわかりやすく解説するブログ
「Curiosity Creates」を運営中。


コメント