

はじめに
「機械学習をやってみたいけど、プログラミングは苦手…」
そんな方におすすめなのが KNIME(ナイム) です。KNIMEは基本無料で使えるソフトで、プログラミング無しでマウス操作により機械学習ができます。
今回は機械学習の中でも「決定木分析」という分かりやすい予測モデルを使って、データ分析の流れを体験してみましょう。
KNIMEは機械学習を行うための優秀なツールですが、初めての方はイメージがわきにくいと思います。まずは、雰囲気をつかむため以下の動画をご覧ください。60秒で決定木分析を行うキャプチャ動画です。
KNIMEについてもう少し知りたい方はこちらの記事もご覧ください。
機械学習モデル作成とは?
まずは、機械学習モデルがどんなものかを簡単に見てみましょう。
機械学習による予測モデルの利用には、大きく分けて次の3つのステップがあります。
- データ準備
現実のデータには未入力や入力ミスが含まれていることが多いため、まずは不備を整えて分析できる状態にします。
そのうえで、予測したい「結果データ」と、その予測に使う「特徴量データ」を用意します。 - 学習(トレーニング)
予測したい結果が含まれるデータ(教師データ)を使い、特徴量と結果の関係性を学習します。
例:患者データの「年齢」「検査値」「既往歴」など(特徴量)と、「再入院した/しなかった」(結果)。 - 予測(推論)
学習で得られた法則性を利用し、新しいデータに対して結果を予測します。
例:新しい患者データを入力すると、その人が再入院する可能性を予測できる。
つまり、**「過去のデータからパターンを学習し、未来のデータに当てはめる」**のが機械学習モデルです。
この記事では2.学習(トレーニング)と3.予測(推論)の部分を中心に、やり方を紹介します。
決定木分析とは?
決定木分析は「条件分岐で予測する」シンプルな方法です。
たとえば病院の患者データをもとに、
- 「年齢が65歳以上なら…」
- 「検査値が基準を超えたら…」
というように、ルールを作って分類していきます。
他の機械学習手法に比べて、なぜその結果になったのかがわかりやすいのが特徴です。初心者にぴったりのモデルです。
KNIMEの画面構成
KNIMEの分析画面は、次のようなものです。赤枠のワークフローエリアにノードを配置・接続して分析を進めていくことになります。
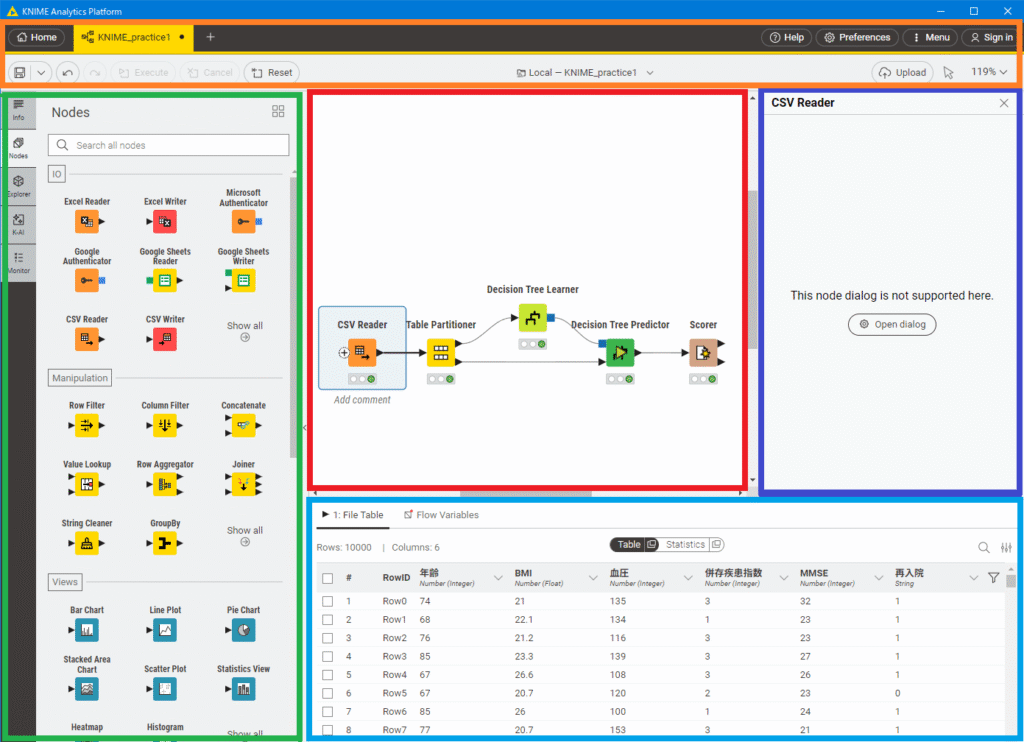
- 上部(オレンジ枠):アンドゥ、リドゥ、保存、ログインやヘルプなど基本ボタン
- 左側(緑枠):info,Nodes,Explorer・・・等のメニューが並びます。分析に使うのはNodesタブです。
- 中央(赤枠):「ワークフロー」…ノードを並べてつなげる作業スペース
- 右側(青枠):設定ウィンドウ
- 下部(水色枠):データ表示エリア
データを読み込んで決定木モデルを作る
新規ワークフローの作成とデータの読み込み
では実際にやってみましょう。
左上のHomeボタンを押してhome画面を表示させ、右側の「Create new workflow」ボタンを押します。
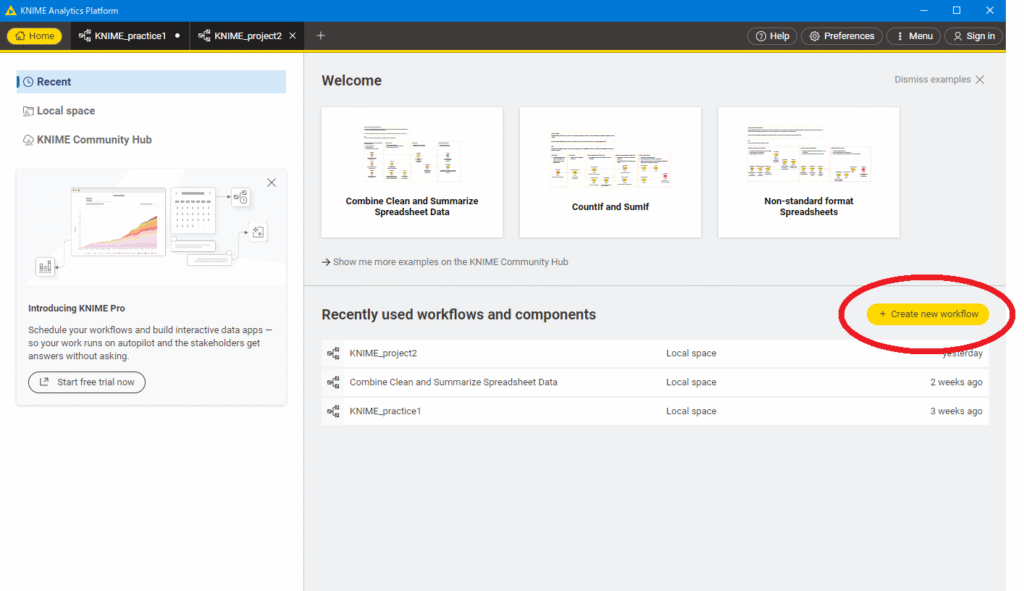
ワークフローの編集画面が表示されたら、分析したいファイルを任意のフォルダからドラッグアンドドロップでワークフローエリアに投入します。今回はCSVファイルですが、エクセルファイルでも構いません。KNIMEが自動的に判断して、適切なノードを配置してくれます。
因みに使用するのはこんなデータです。
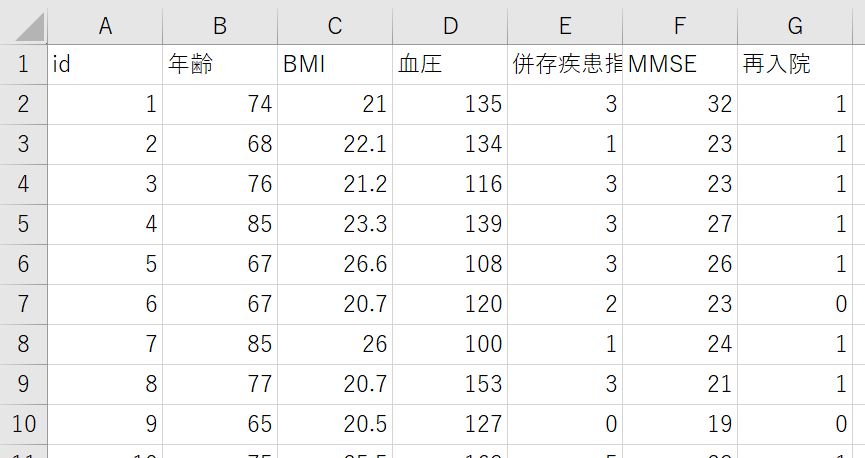
年齢・BMI・血圧・併存実感指数・MMSEから再入院するかどうかを判定するモデルを作成します。再入院ありなら1,再入院無しなら0が再入院列に記載されています。
なお、このデータはプログラムで機械的に生成した架空の物です。実際の病態や患者像を反映したものではありません。ご注意ください。
ノードの配置と接続
ノードの配置は、画面左側のNodeタブから行います。大量のノードが表示されて探しにくいため、検索欄に「csv」や「decision」と入力して絞り込むのがおすすめです。
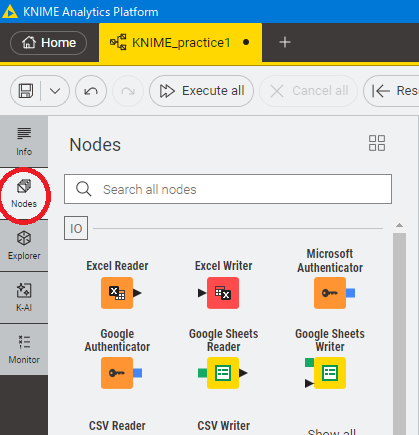
使用するのは以下のノードです。Nodesタブから順次追加してください。
なお、CSV Readerはファイルをドラッグアンドドロップした時点で自動的に追加されるため、Nodesタブから手動で追加する必要はありません。
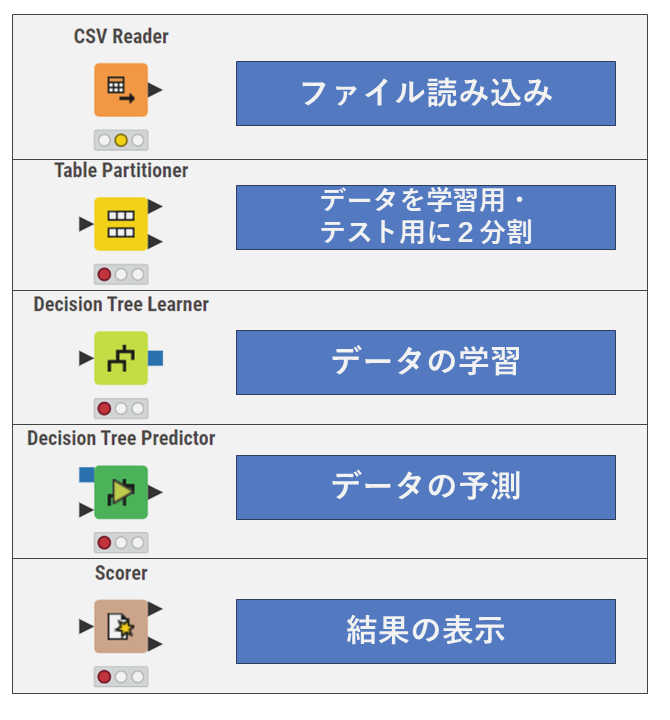
これらのノードを画像のように配置・接続します。接続はノードの右側にある三角または四角のアイコンをマウスでドラッグアンドドロップすることで行います。
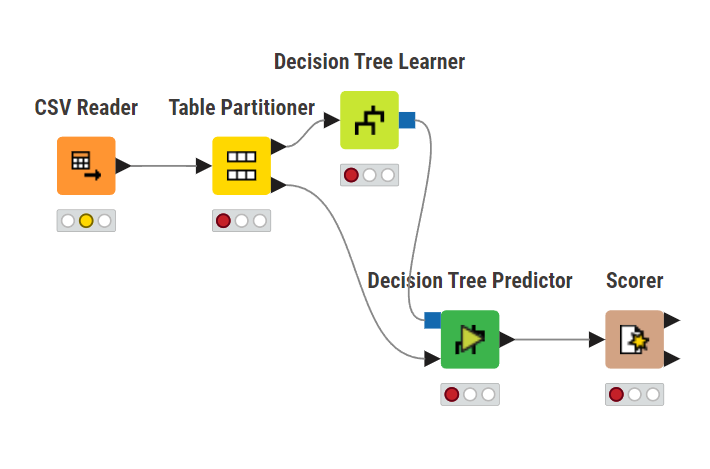
各ノードには四角と三角の接続アイコンがあります。これらの接続アイコンは同じ形同士しか接続できません。
注意が必要なのは「Table Partitioner」の接続です。「Table Partitioner」ノードの右上から出る矢印を「Decision Tree Learner」へ、ノードの右下から出る矢印を「Decision Tree Predictor」へ接続します。逆につなぐと、モデルの精度が下がってしまいます。
設定
概要
各ノードには状態を表す信号のアイコンがついています。
信号アイコンが赤になっている場合、上流のノードで問題が生じている場合もあります。注意してください。
ノードが正常に作動しているか分かりやすいように、画面上で左側のノードから設定・実行をしていきます。ノードについている信号が赤や黄色から緑になれば、そのノードは実行完了です。
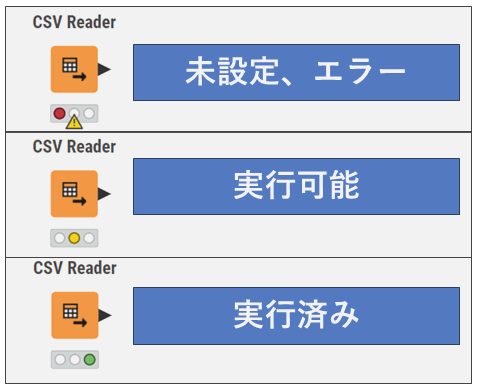
今回、設定が必要なのはCSV ReaderノードとScoreノードです。
設定画面は各ノードのダブルクリックで開けます。(一部クリックのみで画面右側に簡易ウィンドウが表示されるものもあります。)
CSV Reader:データの選択
CSV Readerノードをダブルクリックすると以下のようなウィンドウが開きます。
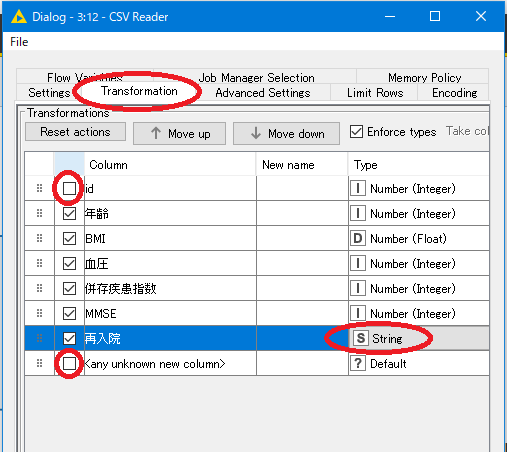
初めは「Setting」タブが開かれている為、ウィンドウ上部の「Transformation」タブを押します。
画面を切り替えたら、不要なデータを分析から外します。必要ないデータのチェックボックスを外してください。今回のデータではid、any unknown new columnが不要です。
次に予測をしたい項目である「再入院」のTypeを確認します。TypeがNumberになっていたら、画像のようにStringにします。データがダミー変数(0か1)で入力されていると、データ型が数値として扱われていることがあります。今回は分類モデルを作成するため、TypeがNumber(Integer)だと後続のノードでエラーが出てしまいます。
※Typeについて:分析の際にデータが整数、小数を含む実数、巨大な整数(21億以上)、文字列、のどのデータ型として扱われているかを示すものです。分析の目的に応じたデータ型を選択する必要があります。
設定が終わったら実行します。
ノードにマウスのポインタを重ねるといくつかアイコンが表示されます。左上の再生ボタンのアイコンを押すとノードが実行されます。(右クリックメニューからExecuteでもOK)
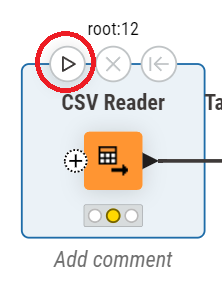
Tabale Partitioner:データの分割
このノードの設定は必須ではありません。特にこだわりが無ければ、そのままアイコンの左上の再生ボタンで実行し次に移りましょう。
初期設定ではデータの70%を学習用に、30パーセントを検証用に振り分ける設定になっています。
ノードをクリックすると右側に設定画面が出るため、必要に応じてデータの振り分け比率を変更してください。Relative Sizeを指定すると、振り分け比率を変更できます。
Decision Tree Learner:データの学習
ノードをダブルクリックして設定画面を開き、予測する項目があっているか確認します。
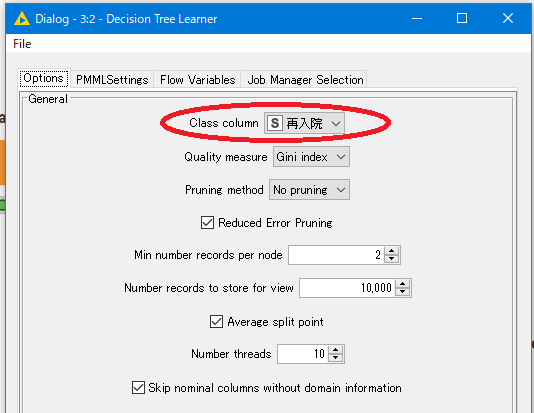
今回は再入院列を予測するのが目的でした。
Class columnが再入院になっています。問題ないため、このままOKボタンでウィンドウを閉じます。
このノードも実行して次に移ります。
Decision Tree Predictor:データの予測
このノードに必要な設定はありません。
このノードも実行して次に移ります。
Score:予測精度の評価
このノードでは正解データと予測値を比較して、予測精度を評価します。
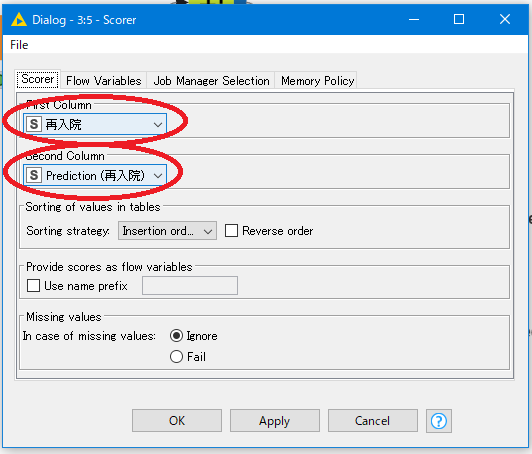
First Column が正解データ、Second Columnがモデルにより予測されたデータです。それぞれ「再入院」と「Prediction(再入院)」が正しく選択されています。
この二つのデータの内、一致しているものが多ければ予測精度が高く、一致しているものが少なければ予測精度が低いことになります。
結果を確認
結果の見方
ノードにマウスポインタを重ねて虫眼鏡のマークが出るものは、そのマークをクリックして結果を確認することが出来ます。ここではDecision Tree LearnerノードとScoreノードのデータ確認方法を紹介します。
Decision Tree Learnerの結果
まずノードにマウスのポインタを重ね、虫眼鏡のマークをクリックします。
この様な図が表示されます(赤や緑は説明のために後から書き込んだものです)。
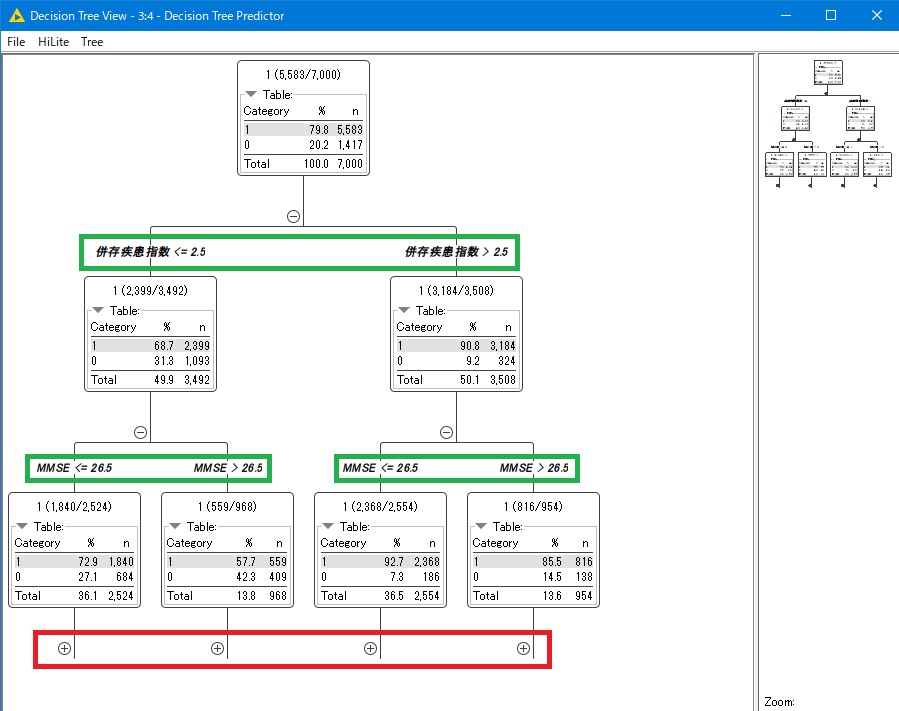
これは決定木分析で作成されたモデルです。学習に使われた7000件のデータがどのように分類されたかが図示されています。
一番上の四角には、学習に使われた7000件のデータが含まれています。ここから条件分岐により、気が枝を広げるような形で判定が分岐していきます。
緑色の四角で囲まれた部分は、分岐の条件です。たとえば一番最初の分岐では、並存疾患指数が2.5より大きければ右下の枝に、そうでなければ左下の枝に分岐します。
条件によっては分岐の回数は非常に多くなります。赤枠で囲った「+」マークをクリックすると下位の分岐を確認出来ます。
では個々のデータ枠を見てみましょう。
赤枠を見てみます。
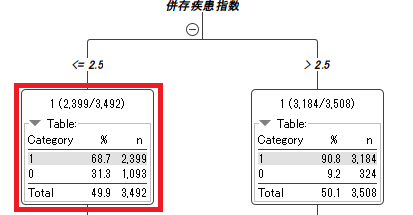
この枠は直前の分岐で並存疾患指数が2.5以下だったデータが含まれています。
この枠には3492件のデータが含まれ、そのうち2399件が1、1093件が0でした。それぞれのパーセンテージも併記されています。
Scoreの結果
Decision Tree Learnerの時と同じく、ポインタをScoreノードに重ねて虫眼鏡マークをクリックしましょう。

こんなウィンドウが表示されます。これは混同行列という、分類モデルの予測結果をまとめた表です。
赤枠が実際のデータ、緑枠が予測値です。実際のデータが1で予測値も1のものが2056件、実際のデータも予測値も0のものが202件あります。これは予測がうまくできた部分です。
一方実際のデータが1で予測値が0だったのが399件、逆のパターンが343件あります。これは予測が外れたものです。
その下の概要を見てみます。Correct classified(正しく予測できた数)は2258件で、Aaccuracy(正解率)は75.267%でした。予測モデルとしては上々と言えるでしょう。
新しいデータで予測して結果を出力する
実際に新しいデータを読み込み、「Decision Tree Predictor」に接続すると、新規のデータに対しても予測ができます。
まずは、新しく予測をしたいデータを、ドラッグアンドドロップでワークフローエリアに投入します。今回はエクセルデータだっため、自動でExcel Readerが使用されています。
Excel Readerノードをダブルクリックして、IDなどの不要なデータ列を除去しましょう。なお、新規データに予測に必要なデータ列が含まれていないとエラーになります。
その他必要なノードをNodesタブから追加して、以下のように配置・接続します。
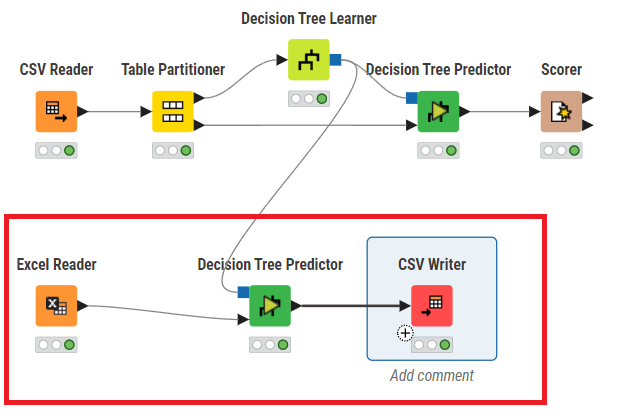
上記の赤枠内が追加した部分です。
ポイントは先ほど配置したDecision Tree Learnerを新しいDecision Tree Predictor に接続する事です。これをしないと予測が出来ません。
CSV Writerノードは、保存フォルダ・ファイル名の指定が必要です。ノードをダブルクリックして、設定画面を開きましょう。
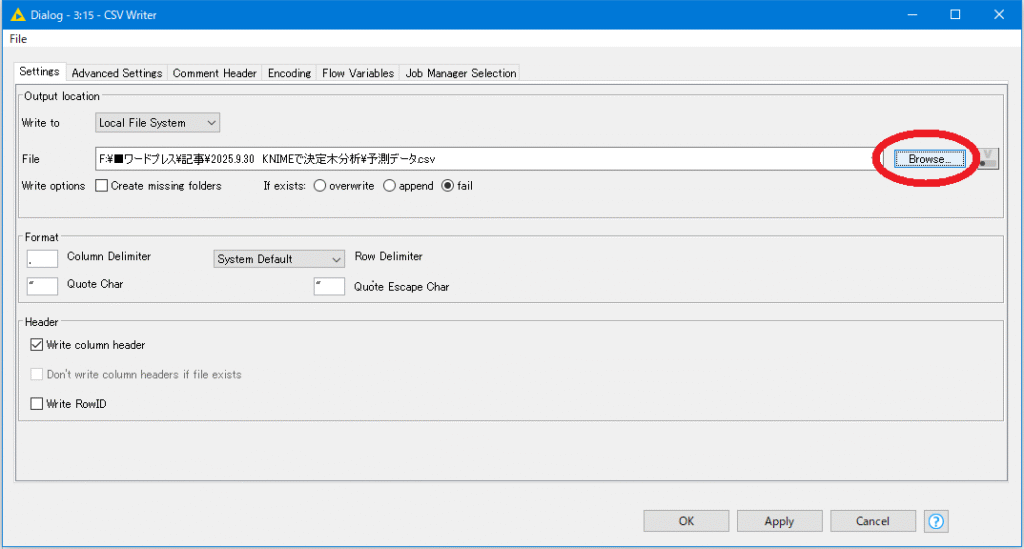
赤丸の部分をクリックすると、保存先を選ぶダイアログが開きます。フォルダとファイル名を入力してOKを押します。
最後にCSV Writerノードを実行すると、指定したフォルダに予測値が追加されたデータが保存されます。
※デフォルト設定では、既に同名ファイルがある場合上書きしせずにエラーを出します。設定を変えながらどんどん上書きしたい場合は、If existsをoverwriteにしましょう。
まとめ
- KNIMEはプログラミング無しで機械学習ができる便利なフリーソフト
- 決定木分析なら「条件分岐で予測する」イメージがつかみやすい
- CSVを読み込んで、学習 → 予測 → 評価の流れをマウス操作だけでできる
プログラミングを使わなくても、ここまでできるのがKNIMEの魅力です。
まずは手元のデータを使って試してみましょう!


コメント