

― なぜ“学習データでは高精度なのに現場で全然ダメ”が起こるのか ―
はじめに:なぜ「過学習」が問題なのか
AIモデルを作ると、多くの人が一度はこう感じます。
「テストでは良さそうなのに、現場では精度がガタ落ち……」
これは単なる誤差ではなく、AI開発で最も注意すべき現象 “過学習” が起きている可能性が高いです。
とくに医療データは、過学習が非常に起こりやすい領域です。
本記事では、医療従事者の方でも直観的に理解できるよう、図解を交えて「過学習とは何か」「なぜダメなのか」「どんな予防策があるのか」をわかりやすく解説します。
過学習とは何か
一言で言うと過学習とは、
学習データの細かい特徴に適合しすぎて、他のデータでは性能が落ちる状態、です。
つまりデータの本質的な傾向ではなく、そのデータ固有のクセ(ノイズ)まで暗記してしまっていることを言います。
例
100人のリハビリ患者データでAIを学習したとします。
このとき、AIが「特定の病院の特有の傾向だけを暗記してしまう」と、別の病院では全く当たらないモデルができてしまいます。
ここから先はグラフを使って、過学習状態では具体的に何が起きているのかを見ていきます。
図解で理解する「過学習」
● 図1:妥当な(汎化性能のある)モデル
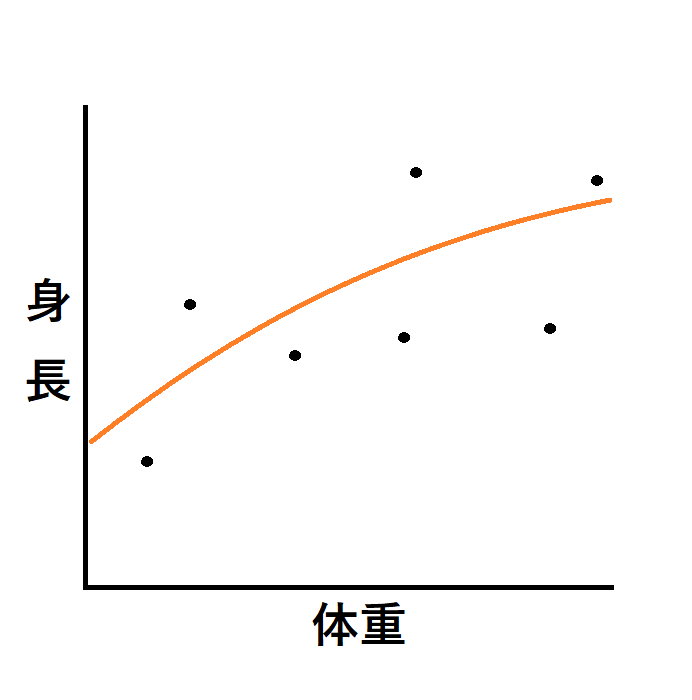
図1はゆるやかな曲線で、データのばらつきをある程度無視しつつ、大まかな関係性を捉えています。
このようなモデルは、初めて見る新しい患者データでも、安定して予測できます。
この状態ではモデルは、「体重が増えるにつれて、身長もなだらかに増えていく。」と学習した状態です。
数値予測をするモデルであれば、数値を滑らかに予測する事が可能です。分類をするモデルであれば、線の上が体重のわりに背の高い細身型・線の下が体重のわりに背が低いマッチョ型と分類できます。
● 図2:過学習したモデル
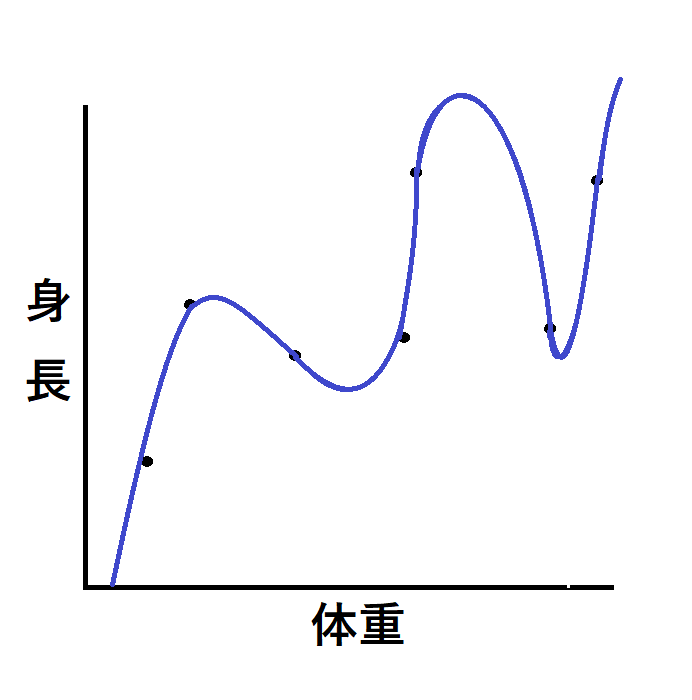
図2の青い線は、データの1点1点に“寄り添いすぎて”曲線が波打っています。
これは精度が良さそうに見えて、実は ノイズまで暗記してしまった状態 です。
上の例と同じ表現をすれば、「体重が増えるにつれて身長も増える傾向だが、時々体重が増えると身長が下がる区間がある。」と学習していることになります。
こうなってしまうと、数値予測モデルでも分類モデルでも新規のデータが来た時に予測が不安定になってしまいます。
● 図3:過学習モデルの予測
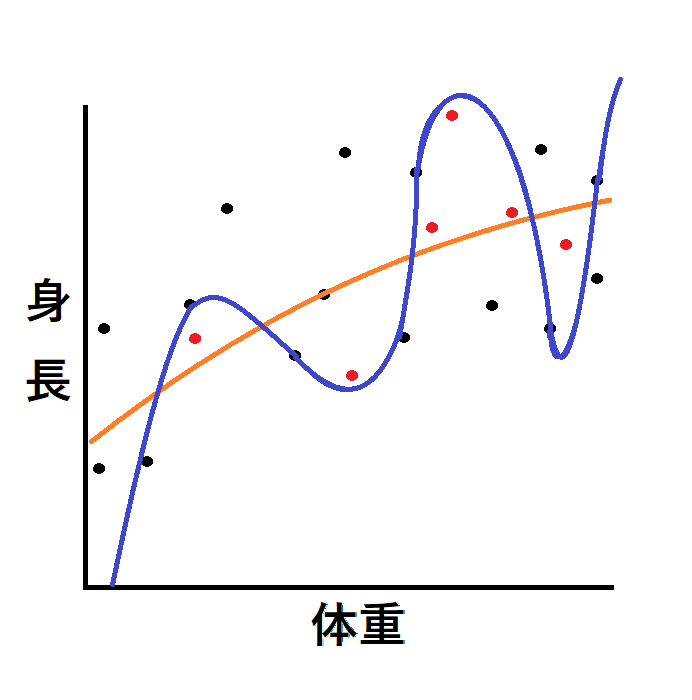
学習データに過剰適合したモデル(青線)は、新しく来た症例の予測を大きく外します。
赤い点は、妥当な学習が出来ているモデル(オレンジ)なら問題なく予測できるが、過学習の青いモデルだと誤判定になってしまうデータです。
これは医療現場では致命的で、
- 重症度予測の誤判定
- 退院時機能の予測のズレ
- 不適切な介入方針の選択
などのリスクにつながります。
分類モデルの場合、
モデルが「線より上=細身型」「線より下=マッチョ型」と判定するとします。
最も高い位置にある赤い点は、本来は“細身型”のサンプルです。
しかし過学習モデル(青線)では線の下側に位置するため、誤って“マッチョ型”と判定されてしまいます。
数値予測モデルでも同様で、
体重の増加に伴う身長の予測値が不安定に上下し、一貫性のないモデルになってしまいます。
過学習はなぜ問題なのか?
以上のように過学習が起こると、学習データ上では高精度に見えても、新規データでの精度が大きく下がります。:
- 分類モデル:誤判定が増える
- 回帰モデル:予測誤差が大きくなる
- 例:生活自立度や転倒リスク予測が大幅にズレる
つまり、作成中は良いように見えるが実践では使えないモデル、となってしまうのです。
過学習が起こる原因
過学習には、発生しやすい条件というのがあります。
データ・モデルの特性・評価の仕方など、それぞれに気を配る必要があります。
● データ面
- データ量が少ない
- 偏りがある(ほとんど高齢者で少数の若年者が混ざっている、など)
- ノイズが多い(評価者差・機器差など)
● モデル面
- モデルが複雑すぎる(深い木、巨大なニューラルネット)
- ハイパーパラメータが不適切
※ハイパーパラメーターとは機械学習モデルの設定のことです。
● 評価面
- 検証方法が悪い(ホールドアウトのみ、外部検証なし)
過学習の見分け方
過学習の兆候はいくつかありますが、一番わかりやすいのは 学習データとテストデータでの成績を、学習の進行に合わせてグラフ化する方法 です。一つのデータセットを学習用とテスト用に分けて行います。
下のグラフは、典型的なディープラーニングモデルでの過学習の例です。
- 青い線:学習データでの成績
- オレンジの線:テストデータでの成績
線が下に下がるほど成績が良いことを示しています。
ディープラーニングモデルは、繰り返し学習を行うことで少しずつ予測精度を向上させます。
初めのうちは、青い線もオレンジの線も急激に低下していきますが、途中から 青い線とオレンジの線が離れてしまう ことがあります。
具体的には、学習データ(青い線)は成績が向上しているのに、テストデータ(オレンジの線)はあまり改善せず、場合によっては悪化してしまう 状態です。
これはモデルが 過学習を起こしているサイン で、学習データに適応しすぎるあまり、テストデータでの成績がかえって下がってしまっている状態です。
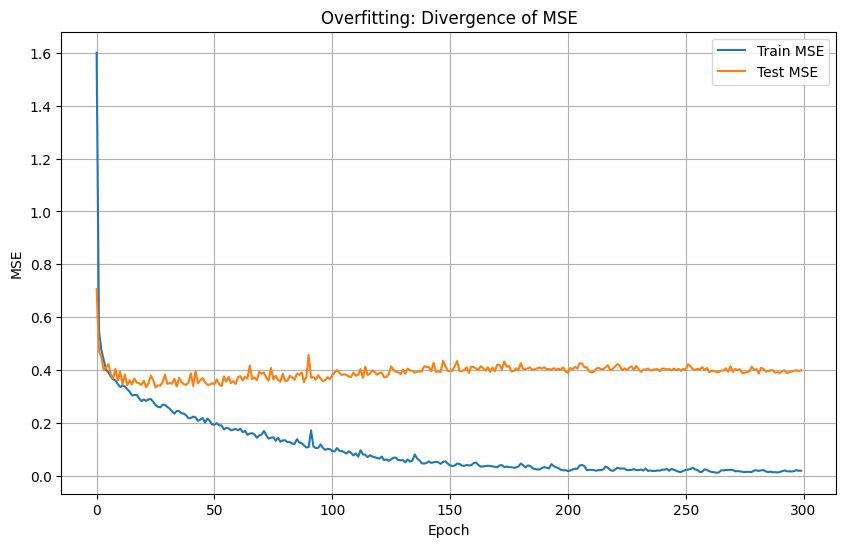
過学習の検証方法は他にもありますが、いずれの方法でも共通しているのは 学習データとは異なるデータで精度を検証すること です。
ただし注意点として、テストデータでの成績は一般に学習データより低い のが普通です。
学習データはモデルが最適化されているため精度が高くなる一方、テストデータは未学習のデータなので、多少成績が下がるのは自然な現象です。
そのため、テストデータの成績が学習データよりわずかに悪いからといって、すぐに過学習と判断するのは早計です。
過学習かどうかを判断するには、学習曲線の形状・データの特性・学習データとテストデータの成績の差などを考慮する 必要があります。最終的には、ある程度の経験や過去の事例を踏まえた判断が重要です。
過学習のチェック方法
- 学習データの精度とテストデータの精度の差が大きいか
- 学習曲線を確認する
- クロスバリデーションで安定しているか確認
- 医療データでは 外部データでの検証(外部バリデーション) が特に重要
過学習を防ぐための基本的な考え方
過学習とは 学習データの細かい特徴を拾い過ぎる ことでした。
したがって対策の方向性は大きく4つです:
- データを増やす(個々のデータの特殊性が目立たなくなる)
- モデルの複雑さを下げる(細かい特徴を拾わない)
- そもそも過学習しにくい手法を使う(回帰分析など)
- アンサンブル学習(モデル同士で過学習傾向を帳消しにする)
過学習対策:具体的な手法
上記のような発想を、具体的な方法に落とし込むと以下のようになります。
● データの工夫
- サンプル数を増やす
- データ拡張(画像・音声・時系列など)
● モデル(複雑さを調整)
- L1/L2 正則化
- Dropout(ディープラーニング)
- Early Stopping
- ハイパーパラメータ最適化(Optunaなど)
以下の表のように、手法により適した調整方法があります。それぞれの方法の詳細は、この記事の範囲を超えている為ここでは触れません。
| 手法 | 過学習リスク | 主な対策(調整すべき項目) |
| LightGBM | 木が深くなりすぎる | num_leaves、min_data_in_leaf |
| XGBoost | 学習率が不適切 | eta、max_depth、Early stopping |
| ランダムフォレスト | 本数不足、深さ過剰 | n_estimators、max_depth |
| ディープラーニング | パラメータ過多 | Dropout、Weight decay、Early stopping |
● 過学習しにくいモデルを選ぶ
- 決定木分析→ ランダムフォレスト
- ディープラーニング → 線形回帰やロジスティック回帰
● アンサンブル学習
- LightGBM + ニューラルネット
- ランダムフォレスト + XGBoost
など、複合モデルで偏りを相殺する
医療データにおける過学習の注意点
最後に、医療データだからこそ発生しやすい問題をまとめます。
- 少数症例・不均衡データにより過学習しやすい
- プライバシー制約でデータ拡張・共有が難しい
- 評価のための外部データが手に入りにくい
対策としては:
- K-fold cross validation
- シンプルなモデル+特徴選択
- 外部データでの検証(外部バリデーション)
この3点が特に有効です。
まとめ
- 過学習とは、学習データの細かい特徴を拾い過ぎて、新しいデータで性能が落ちる状態。
- 医療データは過学習が特に起こりやすい
- 過学習を抑えるには、データを増やす・モデルを変える・適切な検証などの方法がある。
過学習は「AI開発の基礎の基礎」です。
しかし医療領域は、データの特性から過学習が起きやすい環境にあります。モデルが本番環境でも性能を発揮できるよう、計画的にモデルの作成を行いましょう。
今後は、個々の機械学習手法で、過学習を抑える方法を紹介していきたいと思います。

【著者について】
理学療法士(回復期リハビリ病棟 12年以上)
統計検定2級・Python 3エンジニア認定(データ分析)取得。
臨床現場でのデータ活用を目的に統計・機械学習を独学。
FIM退院予測モデルを個人で設計・実装(スタッキングアンサンブル+SHAP)。
強化学習(MuJoCo/Walker2d)や高位頸髄損傷患者向けデバイスの
自作など、臨床課題を技術で解くことに関心を持つ。
医療職向けに統計・データサイエンスをわかりやすく解説するブログ
「Curiosity Creates」を運営中。


コメント