

近年、医療の世界でも「機械学習」や「予測モデル」の活用が注目されています。たとえば、患者の転倒リスク、疾患のスクリーニング、退院時の自立度などを予測するモデルが登場し、学会や論文で頻繁に紹介されるようになってきました。
しかし、こうしたモデルを評価するための「指標」は、専門的な言葉が多く、なじみのない医療従事者にとっては「難しそう……」と感じてしまうこともあるでしょう。
この記事では、**分類モデル(Yes / Noの判定)**に使われる代表的な評価指標について、やさしく解説していきます。
なお、回帰モデル(数値予測モデル)の評価指標についてはこちらの記事で紹介しています。
分類モデルとは何をするものか?
分類モデルとは、複数のデータ(例:年齢、検査値、既往歴など)から、対象が複数のカテゴリのどれに属するかを推定する仕組みです。
たとえば、「疾患あり or なし」「転倒する or しない」「自立・一部介助・全介助」など、カテゴリ分類を行うモデルを指します。
特に、Yes / No の2択で分類するものは**「二値分類(二クラス分類)」と呼ばれます。この場合、モデルは「陽性(Yes)」となる確率**を出力し、あらかじめ定めた基準(例:0.5)を超えていれば「陽性」、そうでなければ「陰性」と判断します。
そして、この分類の精度を評価するための指標があります。よく目にする代表的なものを以下で紹介します。
________________________________________
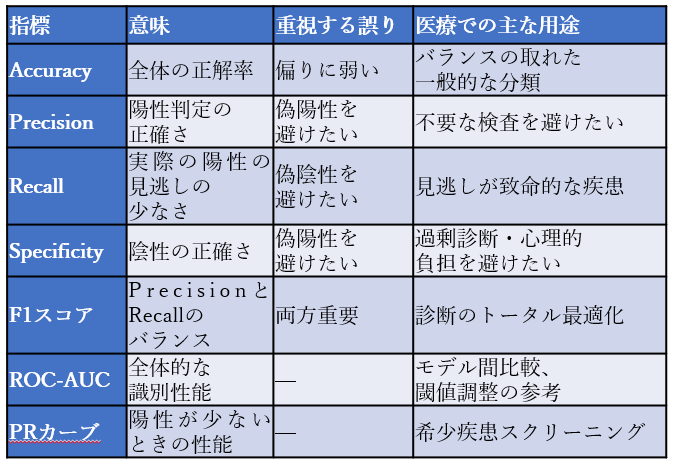
Accuracy(正解率)
定義: 全体の中で、正しく判定できた割合。
式:(TP + TN)÷(TP + TN + FP + FN)
•最もシンプルで直感的な指標です。
•ただし、例えば「99%が陰性」というような不均衡なデータでは、陽性を全く検出しなくても高いAccuracyが出てしまうため注意が必要です。
🩺 医療での例:
風邪かどうかを判定する簡易スクリーニングなど、全体のバランスが良い場面では有用です。
________________________________________
Precision(適合率/陽性的中率)
定義: 陽性と予測されたものの中で、実際に陽性だった割合。
式: TP ÷(TP + FP)
•偽陽性(誤って陽性)を避けたい場面に重要。
•精密検査が高コストや高リスクの場合には、無駄な陽性判定を減らしたいですよね。
🩺 医療での例:
がんの一次スクリーニング検査など。陽性と出た患者には精密検査が必要になるので、誤って陽性にするのは避けたいです。
________________________________________
Recall(感度/再現率)
定義: 実際に陽性であったもののうち、どれだけ見つけられたか。
式: TP ÷(TP + FN)
•見逃し(偽陰性)を減らすことに重きを置いた指標です。
•病気の見逃しは命取り。感度が低いと、患者に深刻な影響を与えることがあります。
🩺 医療での例:
心筋梗塞や脳卒中など、絶対に見逃せない疾患のスクリーニング。
________________________________________
Specificity(特異度)
定義: 実際に陰性だったもののうち、正しく陰性と判定できた割合。
式: TN ÷(TN + FP)
•陽性と誤判定することで余計な検査や不安を与えるリスクを抑えたいときに重要です。
🩺 医療での例:
がん検診などで、健康な人を間違って陽性にしないことが重要な場面。
________________________________________
F1スコア(調和平均)
定義: PrecisionとRecallの調和平均
式: 2 × (Precision × Recall) ÷ (Precision + Recall)
•PrecisionとRecallのどちらも重視する必要があるときに便利。
•どちらか一方に偏らず、全体のバランスを評価できます。
🩺 医療での例:
PCR検査やスクリーニング検査で、見逃しと過剰診断の両方を最小限に抑えたい場面。
________________________________________
ROC曲線とAUC(Area Under the Curve)
•ROC曲線とは、さまざまなしきい値での感度と(1−特異度)をプロットしたもの。
•AUCはその面積で、1に近いほど優秀なモデルとされます。
🩺 医療での例:
糖尿病や心疾患など、スコア型でリスク評価を行うモデルの全体的な性能比較。
________________________________________
PRカーブ(Precision-Recall曲線)
•不均衡データ(陽性が少ない場合)に適した評価。
•Recallを上げたとき、Precisionがどのように下がるかのトレードオフが視覚的にわかります。
🩺 医療での例:
希少疾患(例:難病)のスクリーニング。AccuracyやROCだけでは見えない性能を把握できます。
________________________________________
Confusion Matrix(混同行列)
混同行列とは、分類モデルの予測と実際の結果を整理した2×2の表です。
この表を見ることで、どのタイプの誤りが多いのか、あるいはどのクラスが正しく判別できているかを把握できます。
画像データを使用して肺がんの有無を判定するモデルを例にとると以下のようになります。
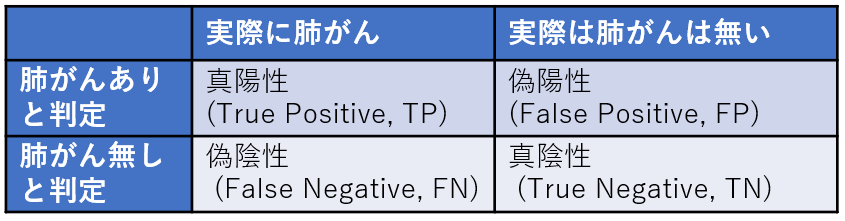
•モデルの誤りの「中身」が見える貴重な表です。
•Accuracyだけでは見落としやすい偏りを確認できます。
医療での例:
転倒リスク予測などで、「誰を見逃しているか」が視覚的にわかる。
________________________________________
各指標の比較一覧
________________________________________
実際の活用で気をつけたいこと(不均衡データ)
均衡データと不均衡データとは?
分類に使うデータのうち、各カテゴリの件数(割合)に偏りがあるかどうかを表す言葉です。
- 均衡データ(Balanced Data):陽性と陰性のデータがほぼ半々(例:50% vs 50%)
- 不均衡データ(Imbalanced Data):一方のデータが圧倒的に少ない(例:陽性5% vs 陰性95%)
医療の現場では、希少疾患や転倒予測など、陽性例が少ないケースが多く、不均衡データに該当します。
指標ごとの挙動の違い(均衡 vs 不均衡データ)
以下の表は、均衡データと不均衡データ(陽性率5%)をそれぞれ1万件生成し、同じ分類モデルで評価したときの主な指標です。
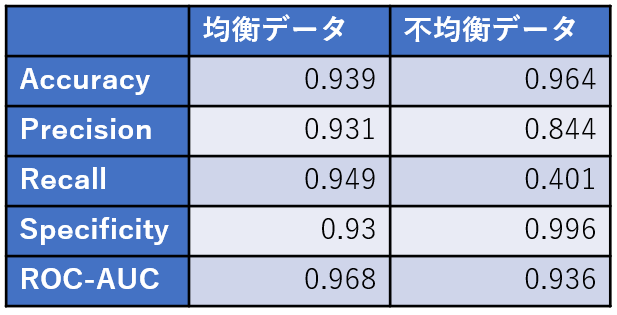
📌 ポイント:
- 不均衡データでは、AccuracyやROC-AUCが高く見えても、Recall(感度)は低い傾向があります。
- 多くのデータが陰性であるため、「すべて陰性と予測」するだけでAccuracyは高くなってしまうのです。
- 特に、がんや心疾患など、少数の陽性を見逃すことが致命的なケースでは、Accuracyだけでは不十分です。
- そのため、RecallやF1スコア、PRカーブ(後述)などを重視する必要があります。
不均衡データにおけるROC曲線とPR曲線
分類モデルの性能を視覚的に確認するために使われるのがROC曲線やPRカーブです。
これらのグラフは、異なる閾値でのモデル性能をプロットして、全体の傾向やトレードオフを確認できます。
- **ROC曲線(感度 vs 1−特異度)**は、全体的な性能を確認するのに適しており、AUC(曲線下の面積)が大きいほど良いモデルです。
- しかし、不均衡データでは、陽性が少なすぎるため、ROCでは精度がよく見えてしまうことがあるのです。
- その場合、**PRカーブ(Precision vs Recall)**の方が適しています。
下図をご覧ください(青:均衡データ、オレンジ:不均衡データ)
上:ROC曲線 下:PRカーブ
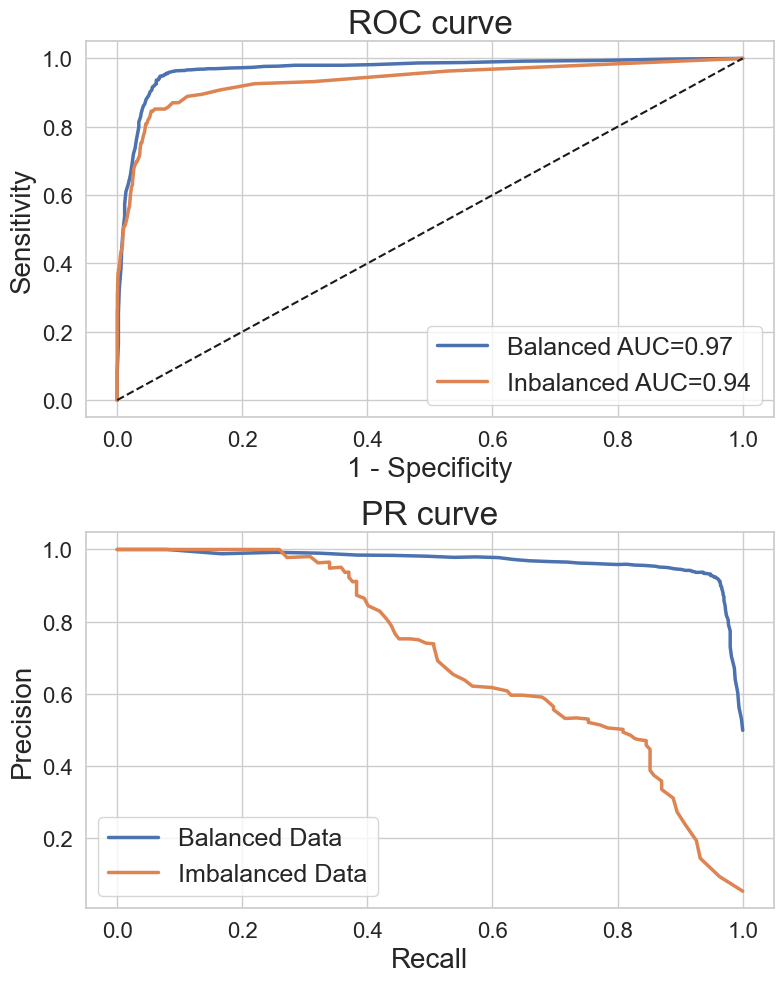
- ROC曲線:両者とも似たような性能に見える
- PR曲線:不均衡データ(オレンジ)の線は左下に大きく下がっており、陽性データの判定精度に問題を抱えていることが分かります
医療でこのようなPRカーブが示された場合、「少数の患者を正しく判定できていない」可能性があります。モデルの採用や信頼性は慎重に検討するべきです。
ROC曲線では不均衡データもそれほど精度は悪くないように見えます。しかし、下半分のPR曲線で確認するとオレンジの不均衡データのプロットは左下に大きく下がっており、少数の陽性データの判定制度に問題を抱えていることが分かります。
________________________________________
まとめ
分類モデルを評価する際、Accuracyだけで判断するのは危険です。
特に医療分野では、陽性患者を見逃すことが致命的になるため、RecallやPRカーブの確認が不可欠です。
✅ あわせて意識したいポイント:
- 混同行列で「誤りの中身」を可視化する
- データが不均衡な場合、AccuracyやROCでは過大評価されやすい
- PRカーブやF1スコアなど、目的に合った指標で判断する
- 分類モデルの目的(例:スクリーニング vs 精密診断)によって、重視すべき指標は異なる
回帰モデルの評価指標にも興味のある方は、こちらの記事をご覧ください。
ちなみに、実はこうした評価指標だけでは、十分にモデルの評価をする事は出来ません。特に「自分のいる組織や部署にとっての善し悪し」を判断するにはこのほかの点にも目を配る必要があります。
こちらの記事では、評価指標に表れないモデルの善し悪しについてのチェックポイントを紹介しています。興味のある方は併せてごらんください。


コメント