

はじめに
この記事では無料で利用可能なデータ分析アプリのKNIMEを使用して、データの前処理を行います。
統計や機械学習の前処理は非常に重要なステップで、データ分析全体の8割以上を占めるともいわれます。
Excelでも前処理は可能ですが、KNIMEを使用すると簡単に前処理が実行可能です。さらに、一度作成した処理フローは再利用ができるため、同様の処理内容であれば次回からは大幅に手間と時間を削減する事ができます。定期的に同様の分析をする場合は特に有効です。
KNIMEについてもう少し詳しく知りたい、という方はこちらの記事をご覧ください。
KNIMEとは?
KNIMEは、アイコンを組み合わせて操作することでデータ操作・機械学習の処理を組み立てることができる分析プラットフォームです。プログラミングをせずに、高度な処理や機械学習モデルを作成することができます。
もう少し詳しく知りたい、という方はこちらの記事をご覧ください。
なぜ前処理が必要なのか
データには欠損や外れ値、異常値が含まれていることが多く、そのままでは正確な分析やモデル作成ができません。
前処理は、データを整えて「機械学習アルゴリズムが理解できる形」にするための重要な工程です。
今回やってみること
この記事では実務でもよく使用される、以下の処理を実行します。
- データ読み込み
- IDを合わせたデータの結合
- 箱ひげ図・散布図でのグラフ化
- 欠損値処理
- 外れ値処理
- 異常値のフィルター処理
- 処理済みデータのCSV出力
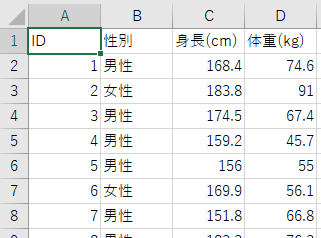
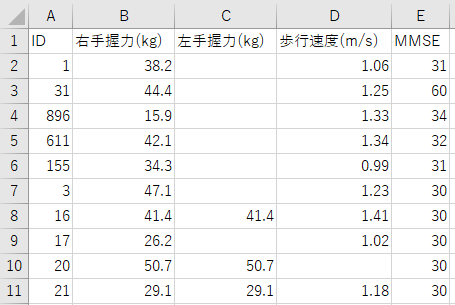
使用するのは以下の二つのデータです。片方には性別や身長などの基礎データが記載され、もう片方のデータには握力やMMSEなどの機能評価の結果が記載されています。
今回使用するノード一覧
黄色いノードはデータ処理(結合、フィルター等)のためのノードです。

青いノードはグラフ作成ノード、赤いノードは外部出力の為のノードです。

ノード操作概要
ノードの処理状態
KNIMEの各ノードにはそれぞれ信号のようなアイコンがついています。ノードの状態が一目で分かるようになっており、以下のような意味があります。
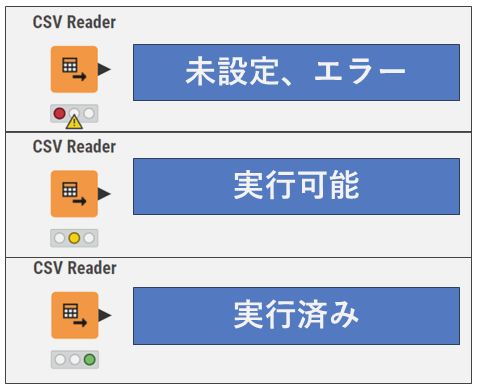
信号アイコンが赤になっている場合、上流のノードで問題が生じている場合もあります。注意してください。
ノードが正常に作動しているか分かりやすいように、画面上で左側のノードから設定・実行をしていきます。ノードについている信号が赤や黄色から緑になれば、そのノードは実行完了です。
ノード上部のボタンアイコン
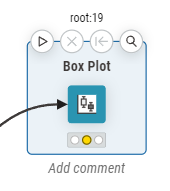
各ノードの上部にはいくつかのボタンアイコンが並んでいます。主に使用するのは左端の再生マークのボタンと、右端の虫眼鏡マークです。虫眼鏡のボタンは表示されないノードもあります。
再生ボタンは設定済みノードの実行に使用します。ノードの設定が終わっても、このボタンを押さないと処理が実行されません。ノードの信号アイコンが黄色の場合に押すことができます。信号アイコンが赤なら設定不備、青なら実行済みの為ボタンを押す事は出来ません。
虫眼鏡ボタンは、結果の表示アイコンです。
今回使用するノードの中では、グラフ作成のアイコンについています。
ノードの信号アイコンが青(または黄色)なら、虫眼鏡ボタンで作成されたグラフを確認する事ができます。
実際のワークフロー作成
ではここからは実際にデータを処理するためのワークフローを作成していきましょう。
まず新規のワークフローを立ち上げます。
編集画面が表示されたら、データの前処理をしたいファイルをドラッグアンドドロップでワークフローエリアに投入します。
次に、処理に必要なノードを配置していきます。
ノードの配置は、画面左側のNodeタブ(赤丸)から行います。大量のノードが表示されて探しにくいため、検索欄に「csv」や「decision」と入力して絞り込むのがおすすめです。
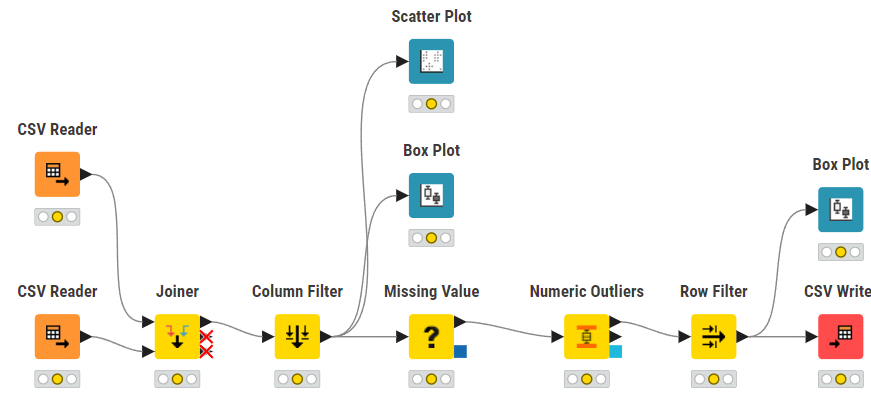
必要なノードを以下のように配置・接続します。
各ノードの設定
CSV Reader
CSVReaderでは、データの読み込みに関する設定を行います。
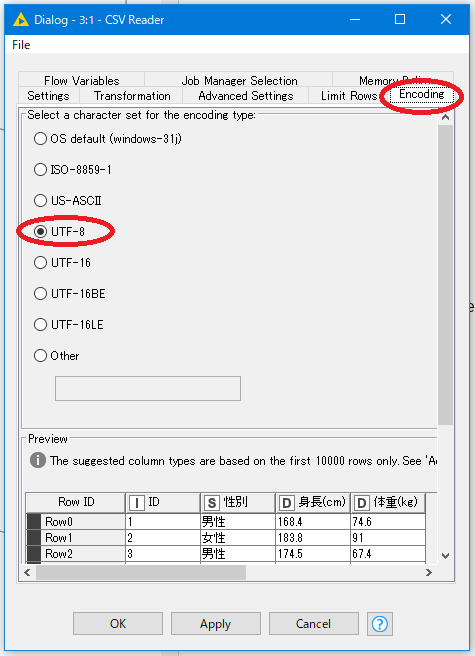
初期設定だと、読み込んだファイルが文字化けする事があります。
その場合は、ノードをダブルクリックして設定画面を開き、赤丸のEncodingタブを開きます。
項目からUTF-8を選択してください。たいていの場合はこれで修正されますが 、これで文字化けが治らない場合は他の文字コードを選択してみてください。(US-ASCII等)
この記事では触れませんが、このノードでデータ列選択・簡単なフィルター処理・データ型の変更なども可能です。
Joiner
このノードでは二つのデータの結合を行います。
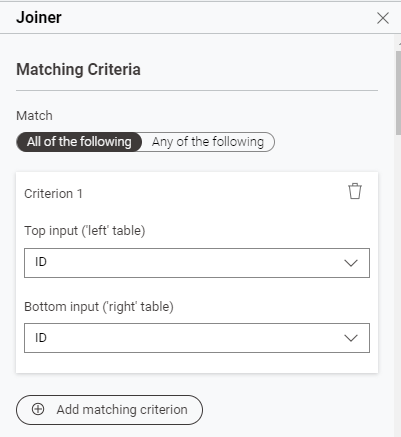
Joinerノードの左上に接続したデータ(Top input)と左下に接続したデータ(Bottom Input)をどのように結合するか指定します。今回は、それぞれのデータに含まれるID列が同じもの同士で結合します。
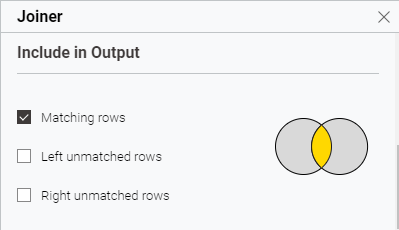
次のノードに渡すのは、両方のデータがそろっているものだけにします。
Column Filter
必要なデータ列を指定します。
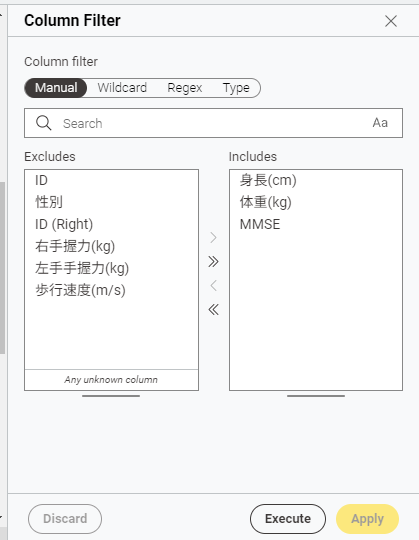
データ列から身長・体重・MMSEを取り出すことにします。
今回は手動で選んでいますが、キーワードやデータ型などで機械的に抽出することも可能です。
データ名で選択する場合はWildcardかRegexを選択し、データ型で選ぶ場合はTypeを選択します。ただ、やや難しい内容になるため、詳しい説明は省きます。
データの概要確認
データが揃ったら概要を確認します。
Column Filterノードを選択しすると、データ数が確認できます。現在のデータ数・列数は左側(赤丸)に表示されており、Rowsが行数、Columnsが列数です。
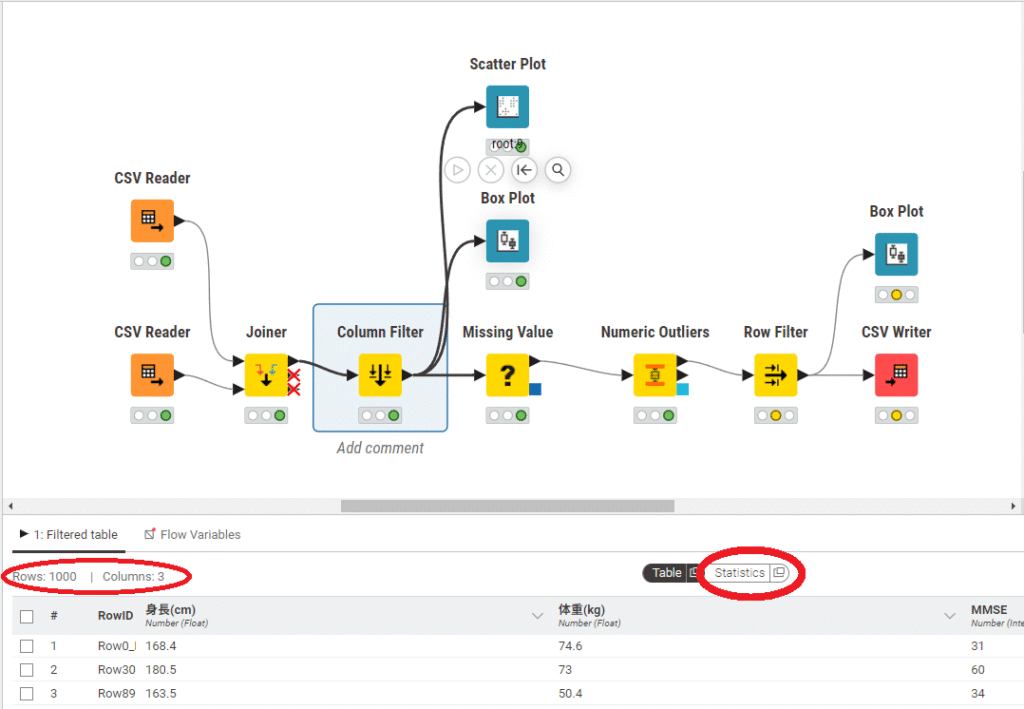
赤丸の「Statistics」ボタンを押すと、さらに詳しいデータの概要が表示されます。
表示された概要は以下のようなものです。
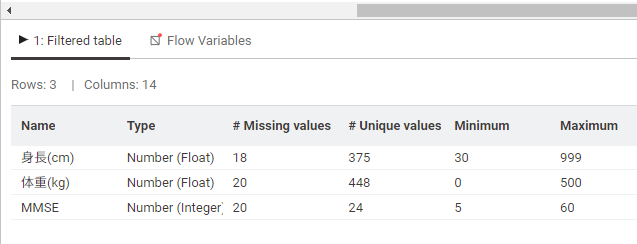
Missing values:欠損データの数
Unique values:重複の無いデータの数
Minimum:最小値
Maximum:最大値
表を右に見ていくと、中央値(Median)や平均値(Mean)、標準偏差(Standard Deviation)、合計(Sum)などがあります。
今回のデータを列ごとに見てみます。
身長・体重・MMSEのどのデータ列も欠損値が20個程度ある様です。
また最小値・最大値を見ると、身長(cm)が30~999,体重が0~500となっており、入力ミスがあることが分かります。
MMSEは認知機能の評価で最大30点のはずですが、最大値は60になっています。
Box Plot/ Scatter Plot
データを数値で確認しましたが、グラフで外れ値を確認することもできます。
Box Plotノードを選択し、画面右側に出る設定ウィンドウから表示する項目を選択します。
グラフに表示したい項目を右側のInludes枠に入れましょう。
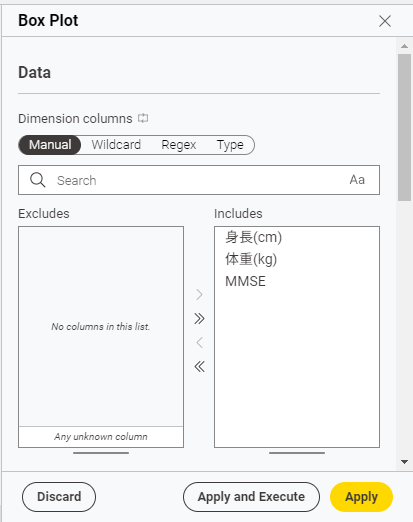
表示するデータを選択したら、下の方にあるApply and Executeボタンを押します。
似たような流れで、Scatter Plotも使用できます。確認したい項目がごく少数だったり時系列データであれば、こちらでもいいかもしれません。
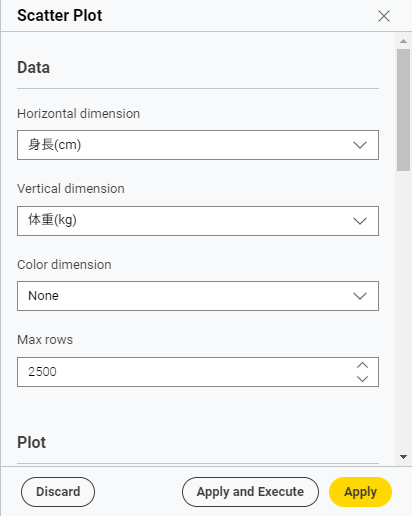
Horizontal dimensionとVertical dimensionで表示したい項目をそれぞれ選択し、Apply and Executeボタンを押します。
データ概要での確認かグラフによる確認を行ったら、次は確認できたデータの不備を処理していきます。
Missing Value
このノードでは欠損値の処理を行います。
今回は欠損データが少ないため、欠損を含む行をすべて削除する方法をとります。Missing Valueノードをダブルクリックすると設定画面が開きます。
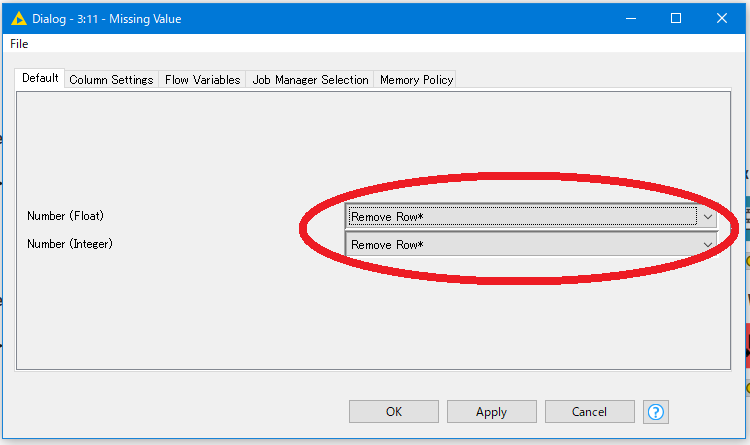
ノードが受け取ったデータに含まれるデータ形式ごとに、欠損値の処理方法を一括で指定できます。削除のほかにも特定のデータ(平均値・中央値・前のデータ等)で埋める方法も選択できます。
また、データ列ごとに個別の処理方法を指定することもできます。そのばあいはウィンドウ上部のColumn Settingタブを押して、以下の画面を開きます。
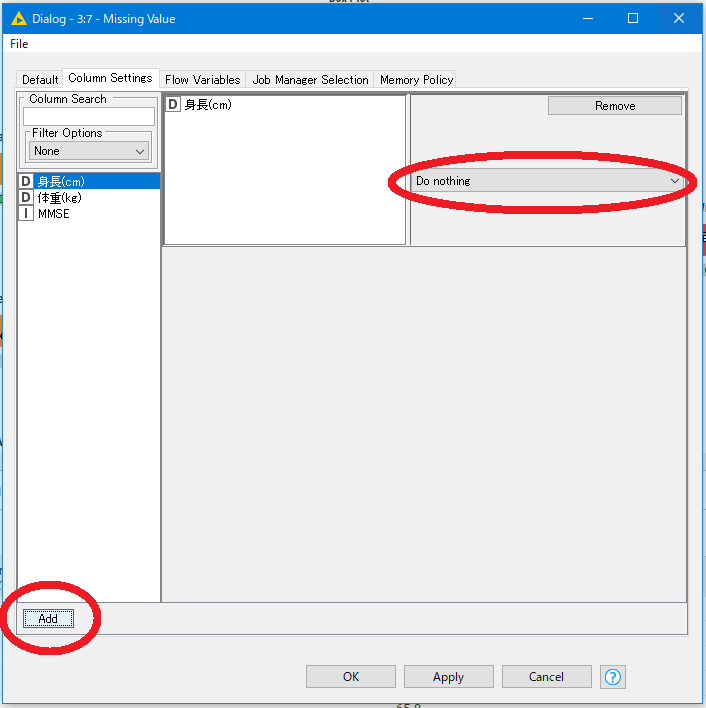
左側に並ぶデータ列から、処理を指定したい項目を選んで左下のAddボタンを押します。
右側に設定枠が出てくるので、Remove Row(行削除)やMean(平均値を代入)など目的に応じた処理方法を指定します。
これで欠損値処理は完了です。
Numeric Outliers
このノードでは外れ値処理を行います。
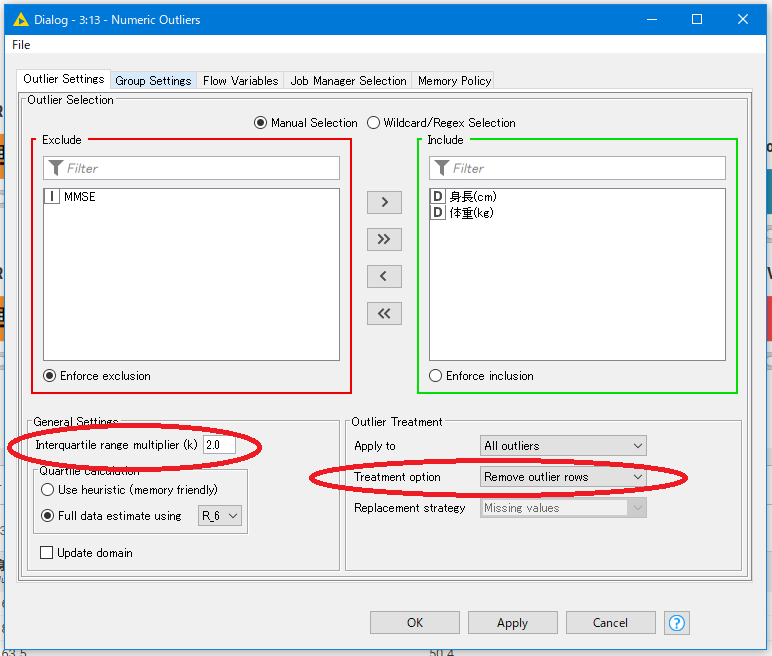
データを選択する枠があるので、外れ値処理を行いたいデータ列をInclude枠へ入れ、処理を適用したくないデータは左のExclude枠へ入れます。
MMSE列はデータが密集しており、分布を利用した外れ値処理がうまく機能しない可能性があります。データの分布に関係なく、MMSEの最大値である30を超えたデータを削除する必要があります。この処理は次のRow Filterノードで行います。
さて、Numeric Outliersの設定です。ウィンドウ左下のInterquartile range multiplierで、外れ値として扱う範囲を指定します。数値を小さくすると、厳しい基準で外れ値判定を行う事になります。大きくすれば基準は緩くなり、多くのデータを解析に含める事になります。
右下のTreatment optionで外れ値に対する処理を選択します。今回は外れ値データを削除するため、Remove outlier rowsを選択します。
Row Filter
このノードでは指定条件で、データのフィルタリングを行います。
今回はMMSE列に含まれる異常値データを削除します。
Row Filterノードを選択すると、画面右側にこのような設定エリアが表示されます。
Add filter criterionボタンを押すと、設定枠が追加されます。
設定枠が追加されたら、Filter Columnでフィルタリングするデータを選択し、Operatorで処理方法を指定し、Valueで処理の境界値を指定します。
今回はMMSEが31点未満のデータを残したいため、以下のように設定しました。
設定が終わったらApply and Executeボタンを押して実行します。
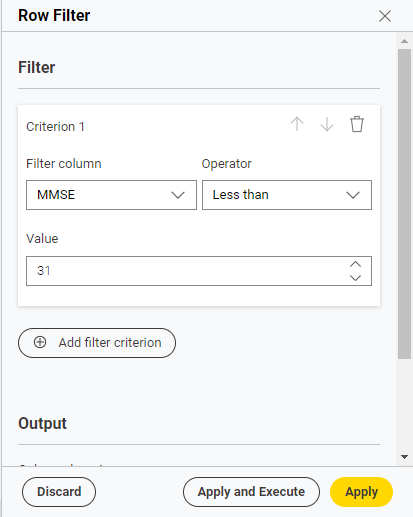
※欠損データがあると、Row Filterノードで自動的に削除されてしまいます。欠損データを残したい場合は、事前にMissing Valueノードで処理をしておきましょう。
CSV Writer
データを利用可能にするための前処理はこれで終了です。
処理済みのデータを外部に出力してみます。
今回はCSV Writerノードを使用して、外部出力を行います。
ノードをダブルクリックすると以下のようなウィンドウが開きます。
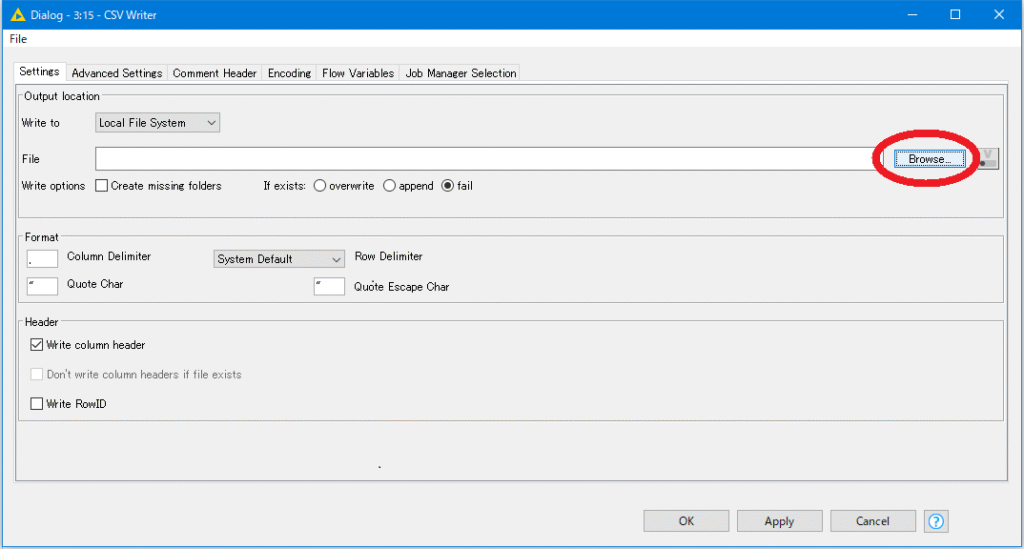
赤丸のボタンで保存先を選択し、ファイル名を入力してOKボタンを押せば出力完了です。
まとめ
この記事では、無料で利用できるデータ分析プラットフォーム KNIME を使って、数値データの前処理を実践しました。前処理は分析や機械学習において非常に重要で、データの品質を整えることで結果の精度や再現性が大きく変わります。
前処理をする上で大事なポイントは以下の部分です。
- 欠損値・外れ値・異常値の処理は分析前の必須ステップ
- グラフや要約統計量を確認することで、入力ミスや異常値を見逃さない
- 作成した処理フローは何度でも再利用でき、効率的なデータ分析に役立つ
上記に注意しながら、KNIMEで簡単データ処理を体験してみて下さい!
前処理が終わって、実際のデータ分析の工程を見てみたい方はこちらの記事(決定木分析、ランダムフォレスト)も併せてごらんください。


コメント