

機械学習モデルを「使える」形に!Streamlitでアプリ化のススメ
モデルを構築し、素晴らしい予測性能を達成したとき、次に考えるのは「このモデルをどうやってみんなに使ってもらうか?」ではないでしょうか。
以前の記事では、機械学習モデルをアプリケーション化する手段としてtkinterを使用したGUI(グラフィカルユーザーインターフェース)の作成をご紹介しました。プログラミングの知識がない方でもモデルを簡単に利用できるようにすることは、データサイエンティストの重要な役割の一つですよね。
今回は、そんなモデルのアプリケーション化に最適なPythonライブラリ Streamlit をご紹介します。Tkinterも素晴らしいライブラリですが、Streamlitは機械学習モデルをブラウザ上で動作させることに特化しており、より手軽にWebアプリとして公開できるのが大きな魅力です。
TkinterとStreamlit、どう使い分ける?
GUIアプリ開発と聞くとTkinterを思い浮かべる方も多いかもしれません。しかし、機械学習モデルのアプリケーション化を考える際には、Streamlitが非常に有力な選択肢となります。両者にはそれぞれ得意・不得意があります。
最小構成で「データの取り込み」「モデルの学習」「学習済みパラメーターの保持」「学習済みモデルでの予測」といった機能をローカルマシンで実行するだけなら、どちらを使っても大きな差はありません。しかし、モデルの公開範囲やUI(ユーザーインターフェース)の柔軟性を考慮すると、その特性が明確になります。
- Tkinter:
- 得意: ローカル環境でのGUIアプリ開発に非常に強い。どのような目的のデスクトップアプリケーションでも開発可能で、UIの自由度も高いのが特徴。
- 苦手: Webアプリなど外部での公開を考えると、追加の手間や知識が必要になる。
- Streamlit:
- 得意: 機械学習モデルを手軽に公開できるように設計されており、シンプルに記述できる。Streamlit Cloudのようなサービスと組み合わせれば、Webアプリとして公開するハードルが非常に低い。
- 苦手: 手の込んだ複雑なUIを作成しようとすると、Tkinterに比べて柔軟性に限界がある。
このような特徴から、将来的にWebアプリとしてモデルを公開することを考えているのであればStreamlitが適しています。一方、限られた環境での利用で、非常に細かく作り込んだGUIが必要な場合はTkinterが適切と言えるでしょう。
「とりあえず機械学習モデルをGUI化してみたい!」という方には、Streamlitが圧倒的におすすめです。最小構成から始め、メニューやデータの読み込み項目を追加していく際にも、Streamlitは要素を追加するだけで自動的にある程度のレイアウトを整えてくれるため、開発の手間が大幅に削減されます。
同じUIを作るならStreamlitがこんなに楽!
では、実際に同じようなUIを作成する場合、StreamlitとTkinterでどれくらいコードの記述量が違うのか見てみましょう。ここでは、名前と年齢を入力して結果を表示する簡単なUIを例に挙げます。
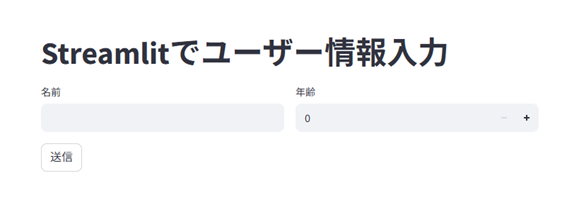
Streamlitで2項目の入力画面を作るとしたらコードはこんな感じ。
Python
import streamlit as st
st.title("Streamlitでユーザー情報入力")
col1, col2 = st.columns(2)
with col1:
name = st.text_input("名前")
with col2:
age = st.number_input("年齢", min_value=0)
if st.button("送信"):
st.write(f"{name}さんは {age}歳です。")
Tkinterで同じことをしようとしたらコードはこんな感じ。
Python
import tkinter as tk
from tkinter import ttk
root = tk.Tk()
root.title("Tkinterでユーザー情報入力")
root.geometry("400x150")
# 2カラムのフレームを作る
frame = ttk.Frame(root)
frame.pack(padx=20, pady=20, fill="x")
# 左カラム(名前ラベル+入力欄)
left_frame = ttk.Frame(frame)
left_frame.pack(side="left", expand=True, fill="both", padx=(0, 10))
ttk.Label(left_frame, text="名前").pack(anchor="w")
entry_name = ttk.Entry(left_frame)
entry_name.pack(fill="x")
# 右カラム(年齢ラベル+入力欄)
right_frame = ttk.Frame(frame)
right_frame.pack(side="left", expand=True, fill="both")
ttk.Label(right_frame, text="年齢").pack(anchor="w")
entry_age = ttk.Spinbox(right_frame, from_=0, to=120)
entry_age.pack(fill="x")
# 送信ボタンと結果表示
def on_submit():
name = entry_name.get()
age = entry_age.get()
if name:
result_label.config(text=f"{name}さんは {age}歳です。")
else:
result_label.config(text="名前を入力してください。")
submit_btn = ttk.Button(root, text="送信", command=on_submit)
submit_btn.pack(pady=10)
result_label = ttk.Label(root, text="")
result_label.pack()
root.mainloop()
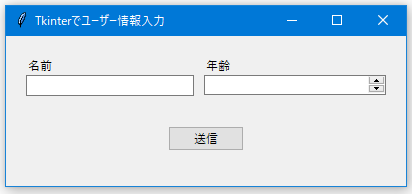
ご覧のように、Tkinterではrootウィンドウの指定や、ウィジェット・ボタンの呼び出し、.packなどのメソッドで位置を明示的に指定するなどの作業が必要です。自由度は高いのですがその分すべて指定する必要があり、Streamlitよりもややコードの量が増える印象です。
Streamlitは「GUIを作るときに細かい指定ができない」という側面もありますが、プロトタイプを作成する段階では、そこまで細かい部分を作り込む必要がない場合がほとんどです。まずはサッと形にして、動くものを見せるという点において、Streamlitは非常に強力です。
Streamlitで予測モデルアプリを作ってみよう!
ここからは、実際にStreamlitを使って機械学習モデルの予測アプリを作る手順をご紹介します。今回は「データの読み込み」「モデルの学習」「学習済みモデルの保持」「学習済みモデルによる予測」という一連の流れをアプリに組み込んでみましょう。
1. プロジェクトのディレクトリ構成
まずは、データの格納やスクリプトの管理のために、以下のようなシンプルなディレクトリ構成を準備します。
your_project/
├── data/
│ └── your_data.csv # 予測に使用するデータなど
├── models/
│ └── trained_model.pkl # 学習済みモデルを保存する場所
└── app.py # Streamlitのメインスクリプト
2. Streamlitスクリプトの作成 (app.py)
app.pyファイルに、Streamlitを使ってデータを読み込み、LightGBMでモデルを学習し、学習済みモデルを保存・ロードして予測を行うコードを記述します。
Python
import streamlit as st
import pandas as pd
import pickle
from sklearn.model_selection import train_test_split
import lightgbm as lgb # LightGBMをインポート
from sklearn.metrics import mean_squared_error # 学習の評価用にインポート
# モデルの読み込み
@st.cache_resource
def load_model(path="models/best_model.pkl"):
try:
with open(path, "rb") as f:
model = pickle.load(f)
return model
except FileNotFoundError:
st.warning("既存のモデルファイルが見つかりませんでした。新しいモデルを学習させてください。")
return None # モデルが見つからない場合はNoneを返す
model = load_model()
st.title("回帰予測アプリ - FIMアウト予測")
# --- 学習用データ読み込みとモデル学習/保存機能 ---
st.header("モデル学習・保存機能")
# 学習用CSVファイルのアップロード
uploaded_train_file = st.file_uploader("学習用CSVファイルをアップロードしてください (オプション)", type=["csv"], key="train_uploader")
if uploaded_train_file is not None:
train_df = pd.read_csv(uploaded_train_file)
st.subheader("アップロードされた学習用データ(一部)")
st.dataframe(train_df.head())
# ターゲット変数と特徴量の選択
st.markdown("---")
st.subheader("学習設定")
target_column = st.selectbox("ターゲット変数を選択してください", train_df.columns)
feature_columns = st.multiselect("特徴量を選択してください", [col for col in train_df.columns if col != target_column])
if st.button("モデルを学習して保存"):
if target_column and feature_columns:
X = train_df[feature_columns]
y = train_df[target_column]
# 訓練データとテストデータに分割 (例: 80%訓練、20%テスト)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# ここをLightGBMモデルに変更
new_model = lgb.LGBMRegressor(random_state=42) # ハイパーパラメータは適宜調整してください
new_model.fit(X_train, y_train)
# モデルの評価 (オプション)
y_pred = new_model.predict(X_test)
rmse = mean_squared_error(y_test, y_pred, squared=False) # RMSEを計算
st.write(f"モデル学習が完了しました。テストセットでのRMSE: {rmse:.2f}")
# 学習済みモデルの保存
model_save_path = "models/new_trained_model.pkl" # 保存パスを適宜変更してください
with open(model_save_path, "wb") as f:
pickle.dump(new_model, f)
st.success(f"新しいモデルが **{model_save_path}** に保存されました。")
# 新しいモデルを現在のセッションで使用するように更新
model = new_model
st.info("予測機能で新しいモデルが使用されます。")
else:
st.warning("ターゲット変数と特徴量をすべて選択してください。")
else:
st.info("学習用CSVファイルをアップロードすると、新しいモデルを学習・保存できます。")
st.markdown("---")
# --- 既存の予測機能 ---
st.header("回帰予測")
# 入力方法の選択
input_type = st.radio("入力方法を選択してください", ("手入力", "CSVアップロード"), key="input_type_prediction")
# 入力データの準備
if input_type == "手入力":
fim_in = st.number_input("FIM入院時点(fim_in)", min_value=0, max_value=126, value=60)
age = st.number_input("年齢(age)", min_value=0, max_value=120, value=80)
mmse = st.number_input("MMSE", min_value=0, max_value=30, value=20)
paralysis = st.selectbox("麻痺の種類(paralysis)", options=[0, 1, 2, 3, 4], format_func=lambda x: f"{x}(例)")
input_df = pd.DataFrame([{
"fim_in": fim_in,
"age": age,
"mmse": mmse,
"paralysis": paralysis
}])
else:
uploaded_file = st.file_uploader("予測用CSVファイルをアップロードしてください", type=["csv"], key="prediction_uploader")
if uploaded_file is not None:
input_df = pd.read_csv(uploaded_file)
else:
input_df = None
# 予測ボタン
if input_df is not None and st.button("予測実行"):
if model is not None:
expected_features = ["fim_in", "age", "mmse", "paralysis"] # 必要なら正確な順番に変更
# アップロードされたCSVの場合、特徴量が揃っているか確認
if not all(feature in input_df.columns for feature in expected_features):
st.error(f"アップロードされたCSVには、必要な特徴量 ({', '.join(expected_features)}) がすべて含まれていません。")
else:
input_df = input_df[expected_features]
preds = model.predict(input_df)
input_df["予測FIMアウト"] = preds
st.subheader("予測結果")
st.dataframe(input_df)
else:
st.warning("モデルがロードされていないか、まだ学習されていません。モデルを学習させるか、既存のモデルをロードしてください。")
3. アプリの実行
app.pyを保存したら、ターミナルやコマンドプロンプトでapp.pyがあるディレクトリに移動し、以下のコマンドを実行します。
Bash
streamlit run app.py
このコマンドを実行すると、自動的にWebブラウザが立ち上がり、作成したStreamlitアプリが表示されます。
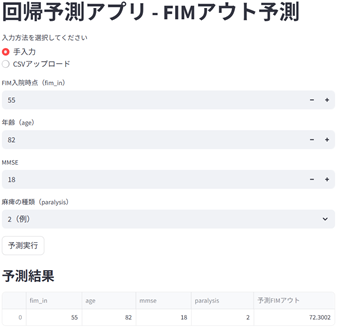
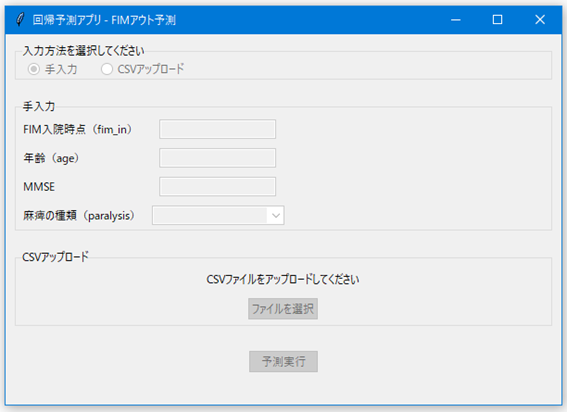
完成したアプリの見た目
実際にこのような手順で作成した予測モデルアプリは、以下のような具合になります。TkinterでGUIを作成するとWindows 95のような古風なデザインになりがちですが、Streamlitの方は少しこなれた、モダンなデザインの印象を受けませんか?
Streamlit
Tkinter
まとめ
Streamlitは、データサイエンスのプロジェクトにおいて、機械学習モデルを手軽にWebアプリケーションとして公開・共有するための強力なツールです。最後に、StreamlitとTkinterの特徴を比較表でまとめておきましょう。
| 観点 | Streamlit | Tkinter |
| 対象ユーザー | データ分析・機械学習の可視化や共有が目的 | デスクトップGUIアプリ開発全般 |
| 起動形式 | コマンドから起動 | .py を直接実行してGUIウィンドウを開く |
| レイアウトの柔軟性 | 簡易的 | 非常に自由だが、手動配置が必要 |
| 見た目の美しさ | デフォルトでモダンで洗練された見た目 | デフォルトではやや古風(Win95風) |
| 学習コスト | 低め。記述がシンプルで自然 | 高め。ウィジェット配置やイベント処理がやや複雑 |
| ユーザーへの配布 | Webアプリにすれば容易 | .exe化すれば配布可能 |
いかがでしたでしょうか?Streamlitを使えば、データサイエンティストが開発したモデルを、より多くの人に「使える」形として提供する道がぐっと開けます。ぜひ、あなたの機械学習モデルをStreamlitでWebアプリ化して、その可能性を広げてみてください!
今後はstreamlitで機械学習モデルのwebアプリの公開の仕方も紹介予定です。


コメント