

声の“中身”を覗くための下調べメモ
構音障害のリハビリに役立つかもしれない――。そんな思いからフォルマント分析アプリを試作した前回の記事では、「声を可視化する仕組み」に主眼を置いて紹介しました。
今回は、その過程で自分なりに調べて理解した音声分析の仕組みや基礎知識について、簡単な備忘録としてまとめておこうと思います。
フォルマントって何?
フォルマントとは、音声のパワースペクトル(周波数分布)の中で特にエネルギーが強くなる帯域を指します。なお、「エネルギーが強い」とは、音の波形の振幅が大きい(その周波数の音が大きい)ことを指します。
周波数の低い方からエネルギーが強い部分を見ていき、第1フォルマント、第2フォルマント、第3フォルマント・・・・・と続きます。特に重要なのは**F1(第1フォルマント)とF2(第2フォルマント)**で、母音の識別に深く関係しています。
第1フォルマントと第2フォルマントは、舌の位置や口唇の開き具合などの声道の形と強く関連しています。それをまとめたのが下の表です。母音に関しては、口唇や舌をどのように動かせば目的の音を発生できるか、フォルマントをもとにある程度判断することが出来ます。
| フォルマント | 関係する発音器官の動き |
|---|---|
| F1 | 口の開き具合(開くとF1が高くなる) |
| F2 | 舌の前後位置(前に出るとF2が高くなる) |
日本語とフォルマントの相性
日本語は「あ・い・う・え・お」の5つの明瞭な母音で構成されており、フォルマントによる判別が比較的しやすい言語といえます。実際にF1・F2をプロットしてみると、それぞれの母音が比較的きれいに分布していて、「これは使えるかも」と思ったのが開発の出発点でした。
一方、子音の判別にはフォルマントだけでは不十分です。破裂音や摩擦音など、短時間かつ非周期的な成分が強いためです。
声を“数値で見る”とは?
声をデジタルで処理するとき、まずは音声信号を時間軸から周波数軸に変換する必要があります。その代表的な方法が**フーリエ変換(FFT)**です。
実際にパワースペクトルを見てみた
少し興味がわいて、実際のパワースペクトル(dBスケール)を描いてみました。実際のパワースペクトルが下のグラフで、次のような特徴が見られました
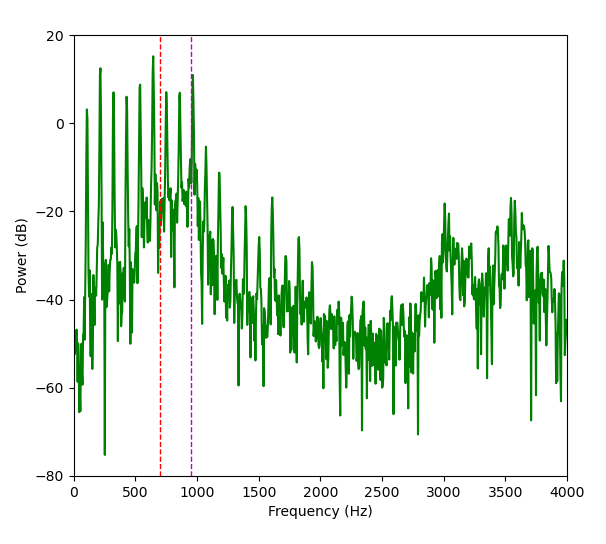
左側に等間隔に並ぶ鋭いスパイクは**基本周波数の倍音**であり、フォルマントではないそうです。声帯が輪ゴムのような単純な構造であれば、発生する音もシンプルな単音だったでしょう。しかし、声帯の構造は様々な弾性や硬さをもつ組織の複雑な複合体であるため、基本周波数だけでなく多くの倍音が自然に発生するそうです。
倍音は基本周波数の整数倍に現れますが、高くなるにつれて目立たなくなり、声道(口や鼻腔など)の構造によって強調された部分が「フォルマント」として現れる――という流れのようです。パワースペクトルからスパイクを除いたなだらかに変化する部分が、倍音が声道により強調・減弱された共振周波数のようです。
声の高さとフォルマント
試しに、少し高め・低めの声を出してみたところ、意外とフォルマント(F1・F2)は大きく変化しませんでした。
これは素人の推測ですが、声道の形状(舌や口の構え)が大きく変わらない限り、声道が増幅できる周波数も変わらないと考えられます。そのため、多少声の高さを変えた程度では、フォルマントにはあまり影響を与えないのだと思われます。
しかし、極端に高く・低くしたときはフォルマントの抽出結果にも変化が現れました。おそらく、倍音が声道の「共鳴しやすい周波数帯」から外れたためでしょう。
LPCとは?フォルマントの抽出法
最初は「フーリエ変換で作ったパワースペクトルの山を順に見ればフォルマントになるのでは?」と安直に考えていましたが、実際はそんなに単純ではありませんでした。
LPC(Linear Predictive Coding)法という数学的な手法が使われているそうです。
- 声道を「周波数特性を持ったフィルタ」としてモデル化し、その共鳴点を計算します。
- フォルマントはこのフィルタの特性(いわゆるポール=極)から推定されます。
正直このあたりはまだ理解が浅いです。
MFCCやメルスペクトログラムという別の特徴量も
**MFCC(メル周波数ケプストラム係数)**も、音声認識でよく使われる特徴量です。
- 人間の耳の周波数感度に合わせたスケール(メルスケール)で、より「聞こえ方」に近い分析が可能。音声分類、話者認識、感情解析など、多くのタスクで利用されています。
- 音声データの特徴量を複数の数値データとして取得できるため、lightGBMなどの機械学習モデルで利用しやすいです。
**メルスペクトログラム**は音声データを画像として表現したものです。実際のメルスペクトログラムは以下のようなものです。下の画像では「いー」と約1秒発音しているときのメルスペクトログラムを表示しています。
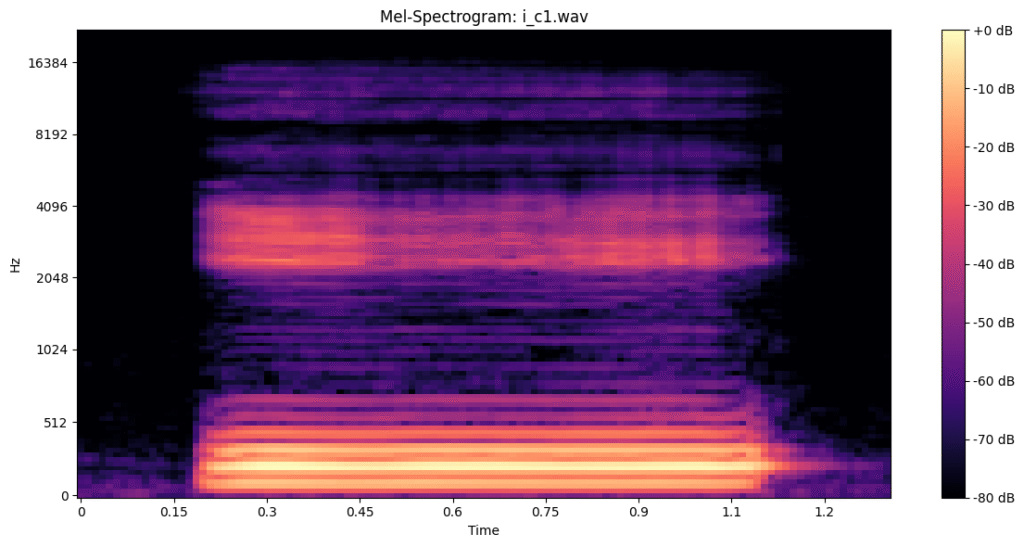
メルスペクトログラムには以下のような特徴があります。
- 縦軸に周波数、横軸を時間にんにして 色がパワーを表現しています。MFCCと同じくメルスケールを使用して周波数を表現しています。
- メルスペクトログラムにすることで、音声を画像データとして解析することが出来ます。
今回のリアルタイム可視化では使用しませんでしたが、別途作成した母音判別モデルではMFCC・メルスペクトログラムを利用してみました。
実験的にやってみたこと
MFCCを入力特徴量としてlightGBMで母音の判別モデルを作成し、メルスペクトログラムを使用したディープラーニングによる母音判別モデルと比較。
LightGBMでは設定が悪かったのか、判別精度はあまり高く出ませんでした。ディープラーニングモデルの方が精度が高く、音声の判別にはメルスペクトログラムによる深層モデルの方が向いているのかもしれません。
ただ、今回のテストでは、著者一人の声のみでモデルを学習・テストしており、サンプルが増えればまた結果も変わってくるかもしれません。
番外編:腹話術とフォルマント?
ちなみに、腹話術のように口をあまり開けずに発音している人たちは、通常の「口唇や舌の動きとフォルマントの対応関係」から外れた音を出しているということになります。
それでも母音のように聞こえるよう発声する技術は、まさに声道の「共鳴のコントロール技術」であり、高度なスキルだと改めて感じました。
まとめ
今回のアプリ開発を通して、「声の可視化」は物理と生理と数理の境界にある面白い世界だと感じました。
音声の特徴量抽出にも様々な方法があることが分かりました。単純なパワースペクトルの描画から、LPCによるフォルマント抽出・MFCC・メルスペクトログラムといった特徴量から、目的に応じた適切な特徴量を選択する事が必要なようです。
また、それぞれの特徴量ごとにノイズに強い・弱いや、構造化データである・ないなどの違いがありデータの取得段階や解析段階でそれぞれに応じた工夫が必要となることも分かりました。
前回の記事で作成したリアルタイムのフォルマント描画スクリプトはテスト段階ですが、今後も修正を繰り返し精度を上げて行きたいですね。


コメント