

学会発表や論文で、下のような赤や青のドットがびっしりと並んだグラフを見かけたことはありませんか。
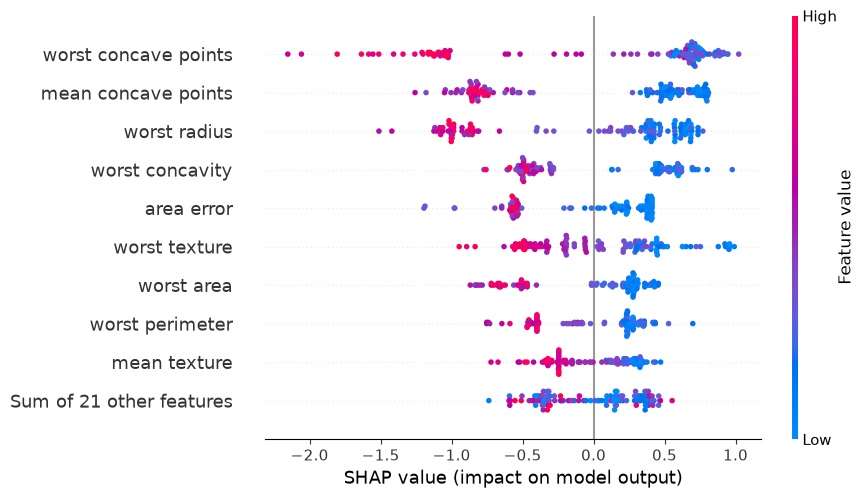
「SHAP値」という言葉が添えられたそのグラフを前に、なんとなく「重要な変数が分かるらしい」ということは理解できても、説明を読んでもどうも腑に落ちない、という経験をした方は少なくないと思います。
実はSHAP値は、まったく新しい統計の概念ではありません。統計解析でよく使用される「偏回帰係数」の発展形として理解すると、驚くほどすっきりと頭に入ってきます。この記事では、SHAP値がなぜ必要とされるのか、そして偏回帰係数とどう違うのかを、臨床の具体例を通して整理していきます。
機械学習のブラックボックス問題と医療
重回帰分析であれば、「年齢の偏回帰係数が-0.5」「FIM入棟時得点の偏回帰係数が+1.2」のように、各変数がどのような影響を持つかが係数という形で明示されます。この透明性があるからこそ、私たちは「この患者さんの予測値が高いのは、主にFIM得点が高いからだ」と説明できます。
一方で、機械学習モデル(LightGBMなど)やディープラーニングは、内部で何百ものパラメータが絡み合いながら予測を作り出しており、人間が直接読み解くことは困難です。これがいわゆる「ブラックボックス問題」です。予測精度がいくら高くても、医療現場でその予測を使うのであれば、「なぜそう判断したのか」を説明できなければ、インフォームドコンセントやチームカンファレンスの場で活用しにくくなってしまいます。
こうした「予測の根拠を人間が理解できるようにする」ための技術全体を、XAI(Explainable AI、説明可能なAI)と呼びます。SHAP値は、このXAIを実現する代表的な手法のひとつです。
SHAP値の直感的理解
SHAP値の背景にあるのは、ゲーム理論における「協力ゲーム」という考え方です。複数のプレイヤーが共同で成果を生み出したとき、その成果を各プレイヤーにどう公平に分配するか、という問題を考える理論です。
これを患者データに当てはめると、「年齢」「FIM得点」「既往歴」といった各変数を“プレイヤー”に見立て、モデルが出す予測値を“共同で生み出した成果”とみなすことができます。SHAP値は、それぞれの変数が「あったとき」と「なかったとき」で予測値がどれだけ変わるか、という差分を、あらゆる変数の組み合わせパターンについて計算し、それを公平に配分した値です。
「その変数が、予測値をどれだけ動かす力を持っていたか」という直感的なイメージを持っていただければ十分です。
SHAP値の数字としての性質
SHAP値という数字に初めて触れると、いくつか戸惑うポイントがあります。ここで整理しておきましょう。
プラス・マイナスの意味
SHAP値は、予測値を押し上げる方向に働けばプラス、押し下げる方向に働けばマイナスの値を取ります。たとえば、ある患者のFIM得点のSHAP値が-3.2であれば、「このFIM得点という情報が、予測スコアを3.2点下げる方向に働いている」ということを意味します。
回帰係数は1回の分析で1セット、SHAP値は症例ごとに計算される
ここは、回帰分析からSHAP値の世界に入ってきた方が最初に引っかかりやすいポイントです。筆者自身も学習を始めた当初、「回帰分析の延長で、変数の数だけSHAP値が出てくるのだろう」と誤解していました。
具体例で考えてみましょう。10人の患者データから、筋力・投薬数・重症度という3つの変数を使ってモデルを作ったとします。
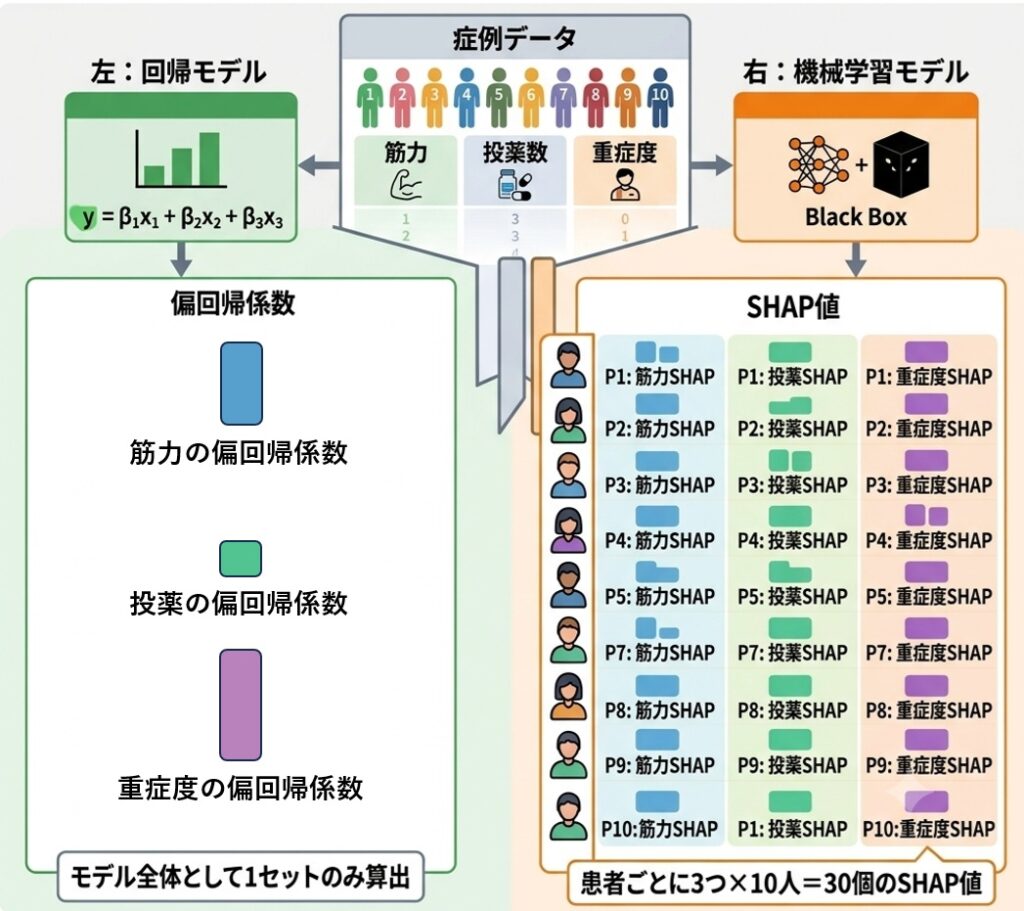
偏回帰係数の場合、患者が何人いようと関係なく、モデル全体としてこの3変数分の偏回帰係数が1セットだけ算出されます。
SHAP値の場合は違います。SHAP値は患者ごとにすべての変数が計算されるため、3変数×10人=30個のSHAP値が生まれることになります。1人の患者につき3つのSHAP値(筋力のSHAP値、投薬数のSHAP値、重症度のSHAP値)が紐づき、それが10人分積み重なる、というイメージです。
絶対値の平均=特徴量重要度
こうして生まれた300個のSHAP値は、患者によって正負どちらの方向にも振れています。ある患者では筋力のSHAP値がプラスに働いていても、別の患者ではマイナスに働いている、ということが起こりえます。
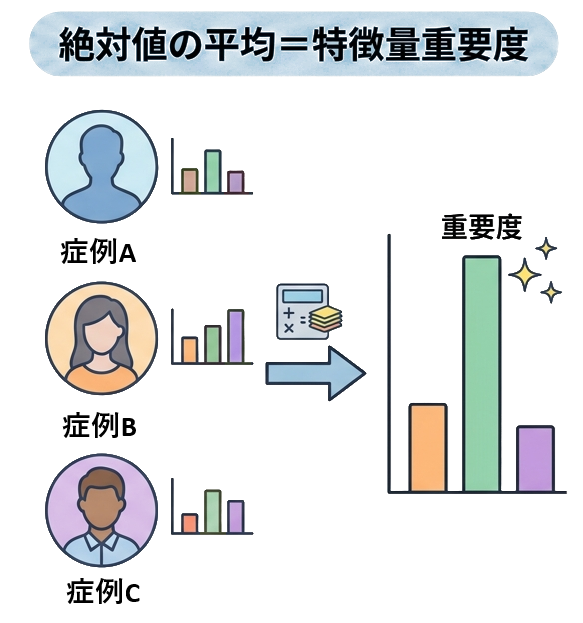
そこで、各変数について全患者分のSHAP値の絶対値を平均すると、「その変数が、全体としてどれだけ予測に影響を与えているか」という重要度の指標が得られます。これは、回帰分析で標準化偏回帰係数の大きさから、どの特徴量がモデルに強く関係しているかを判断する考え方と似ています。ただし、SHAP値は非線形な関係や個々の患者ごとの違いも含めて評価できる点が特徴です。
単位・範囲:回帰モデルの場合
予測対象が連続値(たとえば退院時のFIM得点)である回帰モデルでは、SHAP値は予測値と同じ単位で出力されます。「このSHAP値はFIM+2.5点分の押し上げ」のように、直感的に読み取ることができます。
単位・範囲:分類モデルの場合
一方、「再転倒の有無」のような分類モデルでは、多くの場合SHAP値はlog-odds(対数オッズ)で出力されます。
ここで注意したいのは、「SHAP値が+1.0だから、確率が1.0(つまり100%)上がる」という解釈は誤りだという点です。対数オッズでの+1.0は、確率に変換すると、元の確率がどこにあるかによって増加量が変わってきます。
たとえば、元の確率が5%の時に対数オッズが1増えると確率は12.6%になりますが、もとが50%の時に対数オッズが1増えると確率は73.1%となります。
SHAP値を確率の感覚で読んでしまうと、思わぬ誤解を生むため、分類モデルを扱う際は注意が必要です。
偏回帰係数とSHAP値の対比
ここまでの内容を踏まえて、偏回帰係数とSHAP値の本質的な違いを整理します。
偏回帰係数は、集団全体に対して「この変数が1単位増えると、平均的に予測値がどれだけ変わるか」を示すものです。いわば、全患者に共通して当てはまる、ひとつの“傾き”です。
SHAP値は、目の前のその患者において、その変数が実際にどれだけ予測値に寄与したかを示すものです。同じ「年齢」という変数であっても、患者Aでは大きくプラスに働き、患者Bではほとんど影響していない、ということが起こりえます。これは、ブースティング系モデルが変数間の非線形な関係や交互作用を捉えられることの裏返しでもあります。
一言でまとめるなら、偏回帰係数は「集団に対する平均的な傾き」、SHAP値は「個人において実現した、個別化された傾き」ということになります。
加算性(local accuracy)という性質
SHAP値には、もう一つ重要な数学的な性質があります。それは「加算性(local accuracy)」と呼ばれるもので、次のような関係が成り立つことを指します。
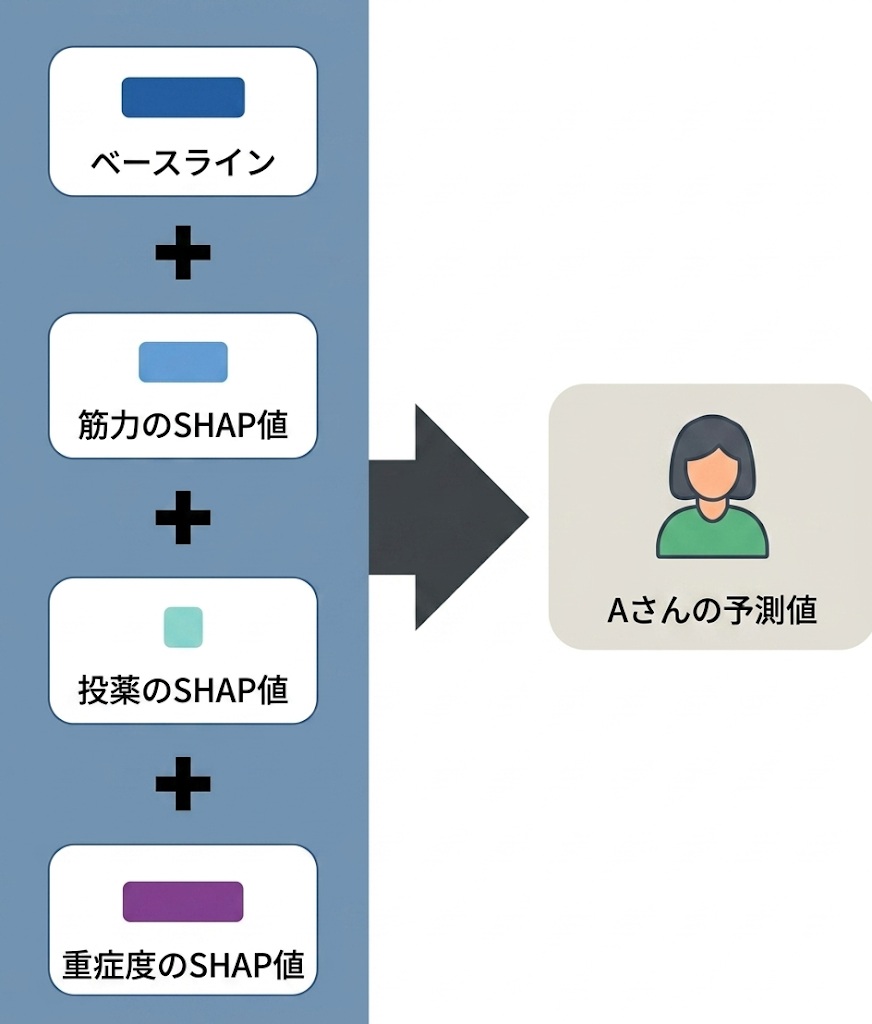
つまり、その患者の予測値は、「みんなの平均値(ベースライン)」を出発点として、各変数のSHAP値を一つずつ足し算(あるいは引き算)していくことで、最終的にぴったりと再現できるのです。この性質があるおかげで、「なぜこの予測値になったのか」を、変数ごとの足し算として分解して説明することができます。
効果量との違い(相関と因果のちがい)
間違えやすい概念に効果量があります。介入研究で使われるCohen’s dのような効果量は、原則として「治療効果」や「曝露効果」の大きさを推定するために設計されています。
一方のSHAP値は、あくまで観察データから作られた予測モデルにおける影響度であり、治療効果や曝露効果そのものを表す値ではありません。
「SHAP値が大きい変数だから、それを変えれば結果が改善する」というのは、SHAP値の使い方としては誤りです。
臨床や実務の現場でSHAP値を提示する際は、「この変数が予測に強く影響している」という事実と、「この変数が原因である」という解釈は、明確に分けて伝える必要があります。
(シミュレーター設置予定)患者データ入力シミュレーター
では、SHAP値がどのようなものか、下の触れるグラフで確認していきましょう。
下のグラフは年齢とアウトカムの予測値への影響をグラフ化したものです。U字のグラフエリアをクリックすると、その年齢での予測値に対する影響度合いが表示されます。
年齢・重症度・交互作用の3つの要素があり、年齢によりそれぞれの配分は変わっていきます。
年齢が高すぎたり低すぎたりすると、年齢の影響が強くなり予測値への寄与度も増えていきます。
まとめ
この記事では、SHAP値が偏回帰係数とどう違うのか、そしてSHAP値という数字をどう読めばよいのかを整理しました。要点を振り返ると、SHAP値には以下のような性質があります。
- SHAP値は患者ごとに計算される個別化された寄与度
- プラス・マイナスの両方を取る
- 絶対値の平均を取ることで特徴量重要度に変換できる
- 加算性によって予測値を足し算として説明できる
- その寄与度はあくまで相関的なものであり、因果関係を意味するものではない

コメント