

はじめに
機械学習モデルは高い予測性能を持つ一方で、
「なぜこの患者さんを高リスクと判断したのか?」
という理由(中身)が分かりにくいことがあります。
SHAP値は、その予測に対して各変数がどの程度影響したのかを分解し、モデルの判断過程を読み解くための方法です。
SHAPには目的に応じて色々なプロット(可視化ツール)があります。
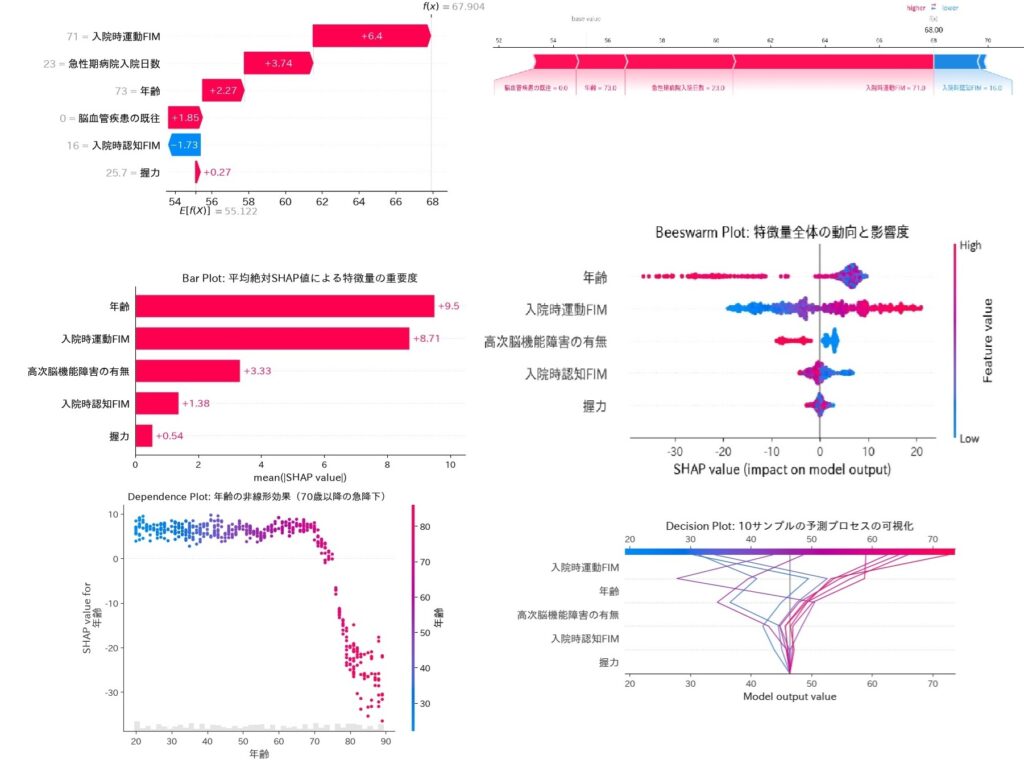
今回この記事で扱うのは、画像にある「Waterfall plot(左上)」と「Force plot(右上)」の2つです。これらは「個別の1人の患者さん」の予測理由を詳しく見ることに特化しています。
(※画像にあるその他のプロットは「全体の傾向」を見るためのものなので、別記事で解説予定です)
Waterfall plot(ウォーターフォールプロット)
➔ 予測値がどの要因の積み重ねで作られたかを、1つずつステップを追って確認する
Force plot(フォースプロット)
➔ 予測を押し上げる要因・押し下げる要因の「パワーバランス」を直感的に把握する
この2つは計算のベースとなるSHAP値こそ同じですが、「見せ方(得意な場面)」が異なります。
この記事では、「この患者さんは、なぜこの予測結果になったのか?」の疑問をスッキリ解決するための、SHAPプロットの正しい読み解き方を解説します。
※この記事で使用しているデータは機械的に生成された架空のものです。臨床の実態を反映するものではありません。
まず「出発点」を理解する——ベースライン E[f(x)] とは何か
Waterfall plotもForce plotも、どちらも 「ベースラインから計算を始めて予測値に到達する」 という同じ構造を持っています。この「ベースライン」の意味を最初にしっかり確認しておきましょう。
Waterfall plotは、身近な例で説明すると銀行口座の明細書のような考え方で理解できます。
| 明細書の概念 | Waterfall plotの対応 |
| 口座の元の残高 | ベースライン: E[f(x)]と書かれることが多いです |
| 各明細(引き落とし・入金) | 各変数のSHAP値 |
| 最終残高 | 最終予測値:f(x)と書かれることが多いです |
銀行の講座では、はじめに元の残高があり、そこから引き落としや入金を計算していくことで現在の残高が出てきます。
SHAP値を使った予測値の理解もこれと同じです。
Waterfallplot(またはforce plot)ではベースラインをスタートにして計算をはじめます。そこから、それぞれの変数(年齢や重症度など)のSHAP値を口座の明細のように足し引きしていきます。足し引きの計算がすべて終わったときに出てくる数値が、その症例の予測値です。
【補足】分類モデルでの注意点 「退院可能か否か」「再入院するか否か」などを予測する分類モデルでは、グラフの単位が確率(%)ではなく、**「対数オッズ(ロジット)」**という数値になっていることがあります。
対数オッズとは、確率を「足し算・引き算ができる形」に変換した、0を中心にプラス・マイナスに広がる数値です。
たとえば、ベースラインが -1.2(対数オッズ)だとすると、これは確率に直すと「約23%」に相当します。 このとき、グラフ上のSHAP値が +0.5 だった場合、これは**「確率が50%上がる」という意味ではありません。**「対数オッズが0.5増える」という意味になります。
対数オッズの +0.5 が確率を何%押し上げるかは、元の確率によって変動します(23%からだと、約33%へ「10%ほど上昇」します)。
※なお、SHAPのプログラムの設定によっては、最初から自動的に「確率(%)」に変換してグラフを描いてくれる場合もあります。もしグラフの基準値(ベースライン)が 0.23(23%)のように確率の数値になっていれば、そのまま%として足し引きして考えて大丈夫です。
Waterfall plot
基本的な構造
ここでは退院時FIMの予測モデルを例にします。
Waterfall plot(瀑布図)は、その名の通り 階段状に滝のように上下する棒グラフ です。
これが「Waterfall plotのスケルトン」です。左の変数名ごとに1段ずつ階段を上り(予測FIM向上)・下り(予測FIM低下)して、ベースラインから最終予測値に到達します。
赤いバーは予測値を上げるもの、青は下げるものです。下の数直線は退院時FIMの予測値のメモリです。
↓
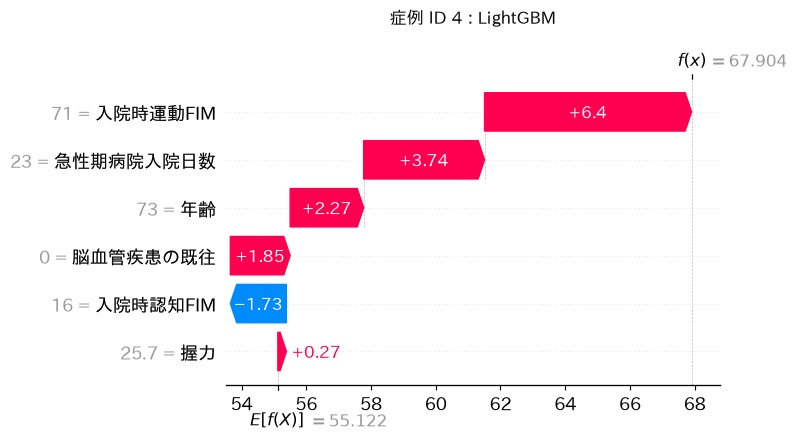
E[f(x)] =55.216日[予測のベースライン]
f(x) = 68.004日 [最終予測値:退院時FIM]
上の例でいえば、
「年齢が73歳だったので予測値が上振れした」
「入院時認知FIMが16と低かったため、予測値が下振れした」
という具合に、1コマずつ因果の流れを追うように読める のがWaterfall plotの最大の強みです。
ちなみにSHAP値におけるベースライン(E[f(x)])は回帰分析における切片のようなものです。「何も情報がなければこの辺になるだろう」という、平均的な予測値を示します。
SHAP値がゼロに近い変数の意味
グラフを見ていると「モデルに投入しているはずなのに、この変数の階段がほぼ動いていない」ということがあります。
これは 「この患者さんにとっては、この変数は予測にほとんど貢献していない」 という意味です。
たとえば認知FIMが28点(満点)の患者さんの場合、認知FIMのSHAP値はほぼゼロになることがあります。「認知が良好→退院困難リスクには寄与しない」という判断をモデルがしているわけです。「なぜ認知FIMが出てこないのか?」という疑問が生じたときは、この解釈を思い出してください。
Waterfall plotが向く場面
- 📋 カンファレンス資料・サマリーシート に入れる
- 📄 患者家族への説明資料 として印刷する
- 🔍 1人の患者さんを深く読み込む ときの思考補助
「時間をかけて丁寧に語る場面」に向いています。
Force plot——ポジティブ/ネガティブ要素の押し合いとして読む
基本的な構造
Force plot(力の図)は、Waterfall plotと 全く同じSHAP値を使いながら、見せ方を水平方向に変えた グラフです。
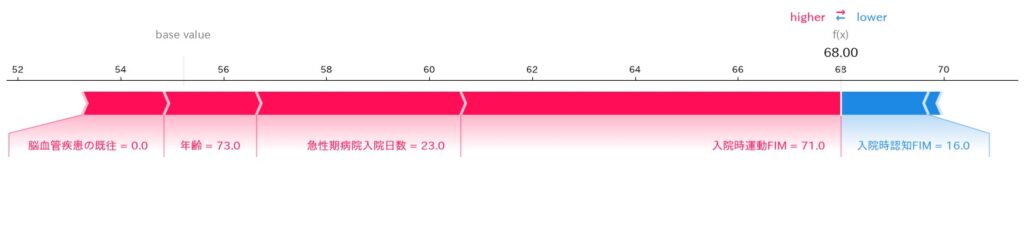
赤色の矢印(特徴)がその症例で「予測値を押し上げるポジティブ要因群」、青色の矢印が 「押し下げるネガティブ要因群」 として、中央のベースラインを挟んで左右から押し合います。最終予測値は、この押し合いの均衡点です。
「1秒の視認性」を活かす
Waterfall plotが明細書なら、Force plotは 「どちらのチームが勝っているか」を一瞬で判定するスコアボード です。
- 赤いブロックが大きい → 「スコアを上げる要素が多い」
- 青いブロックが大きい → 「スコアを下げる要因が支配的」
上の例であれば、数値を1つずつ追わなくてもパッと見で「この患者さんの予測ではポジティブな要素が多く、予測が上振れしている」と伝わるのがForce plotの強みです。
重要な大前提:「数字は全く同じ」
ここは必ず押さえておきたいポイントです。
Waterfall plotとForce plotは、全く同じSHAP値を使っています。「見せ方」が違うだけです。
見た目が全然違うので別のグラフに見えますが、中身の数値は1ミリも変わっていません。SHAP値のバーを縦に並べたか横に並べたかの違いです。
下のグラフでタブを切り替え、イメージをつかんでみましょう。それぞれのプロットボタンを押すと、waterfall plot/force plotが切り替わるようになっています。
Force plotが向く場面
- 🖥️ 電子カルテのダッシュボード に組み込む
- 👥 複数症例を並べて比較スクリーニング するとき
- ⏱️ 短時間のミーティング で素早く共有するとき
「流し見・比較・素早い判断」に向いています。
使い分け判断フロー
実際の場面でどちらを使えばいいか、以下のフローで考えてみてください。
今、どんな場面ですか?
│
├─【1人の患者さんについて深く説明したい】
│ │
│ ├─ 資料・カルテ記録・カンファレンス資料に残したい
│ │ └─ → Waterfall plot ✅
│ │
│ └─ 口頭で素早くチームに共有したい
│ └─ → Force plot ✅
│
└─【複数の患者さんを比較・スクリーニングしたい】
│ └─ → Force plot(並列表示)✅
│
└─ 全患者の集団傾向を見たい
└─ → Summary plot / Dependence plot(次回記事)
臨床や現場での応用と注意点
【最重要】SHAP値が大きい変数が「治療ターゲット」ではない
個別症例のグラフが綺麗に見えれば見えるほど、ついやってしまいがちな誤解があります。
❌ 「年齢のSHAP値が高い → 年齢を若くすれば退院できる」(変えられない) ❌ 「酸塩基平衡の崩れが大きなSHAP値となっている→pHを補正すれば状態が改善する」(因果関係ではない。)
SHAP値は 「このモデルが、この変数をどれだけ予測に使っているか」 を示すものです。「その変数を変えれば予測も変わる」という因果関係を示すものではありません。
変えられない変数(年齢・既往症・発症前の状態)がSHAP値上位に来ても、それは「この予測をするときにその変数が役立つ」という事実に過ぎません。介入の根拠にするためには、SHAP値とは別に因果推論の枠組みが必要です。
対数オッズがわかりにくい
何らかのスコアや数値の予測モデルであれば、SHAP値はそのままスコアの上がり幅/下がり幅を表現しています。
しかし、分類モデルの場合には、デフォルト設定だと分類の確率ではなく対数オッズが出力されます(確率で出力することもできます)。確率と違い、対数オッズは非常にわかりにくい数値であるため他スタッフに伝える場合には誤解が無いように注意が必要です。
【応用】同じ患者を別のモデルで予測するとSHAP値はどう変わるか
ここまで読んでいただいた方へ、さらに深い理解のために。
実はモデルによってSHAP値が大きく変わることがあります。
試しに同じデータセットをランダムフォレストとLightGBMの2つのモデルに通して、同じ症例のSHAP値を比較してみましょう。
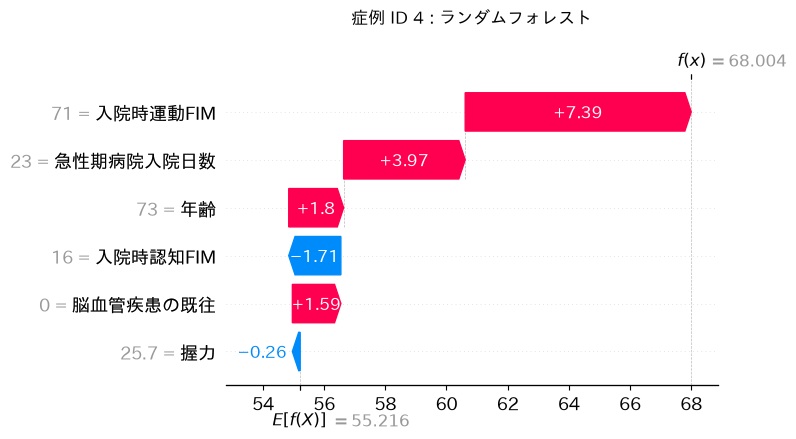
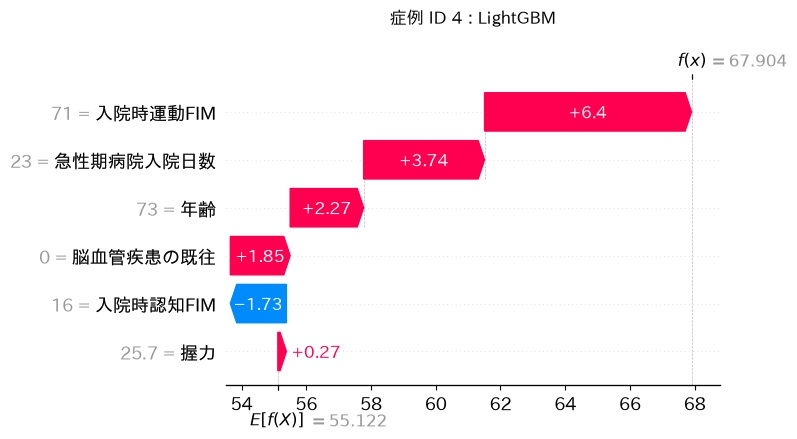
どちらも決定木をベースとしたアンサンブルモデルです。しかし、ランダムフォレストとLightGBMでは「脳血管疾患の既往」と「入院時認知FIM」の順序が入れ替わっており、握力のSHAP値も正負が入れ替わっています。これは何を意味するのでしょうか?
同じデータを見ても、「どう読むか」はモデルの種類によって異なるのです。SHAP値はあくまでも「そのモデルの説明」であり、「データの真実の構造」ではない
Waterfall plotが綺麗で説得力があるほど、「これが正解だ」と思いたくなります。しかし常に「グラフはこのモデルにおける解釈であり、別なモデルなら変わりうる」という認識を持っておくことが大切です。
【コラム】なぜSHAP値は相関する変数に強いのか
(ここは読み飛ばしても本文の理解には影響しません)
従来の「特徴量重要度」の落とし穴
XGBoostやランダムフォレストなどの機械学習モデルには、もともと特徴量重要度(Feature Importance)という指標があります。しかし臨床データでは注意点があります。似た性質の変数が複数ある場合、1つだけが重要と評価され、他の変数の影響が見えにくくなる、という点です。
たとえば、「握力」と「膝伸展筋力」がどちらも退院困難に同じくらい関係しているとします。決定木ベースのモデルは、「まず握力で分岐しよう」と選ぶと、次の分岐では「握力で分けた後の残りのバリエーション」しか残っておらず、膝伸展筋力の重要度が極端に低く見積もられてしまいます。
SHAP値はゲーム理論で公平に分配する
SHAP値の計算の元になっているShapley値は、ゲーム理論の「公平な報酬分配」から来ています。
考え方はシンプルです:「握力だけで予測した場合」「膝伸展筋力だけで予測した場合」「両方使った場合」「どちらも使わない場合」の全パターンを計算して平均を取る。
これにより、「先に使われたか後に使われたか」という順番の有利・不利がなくなり、相関する2つの変数に公平にSHAP値が分配されます。握力も膝伸展筋力も、実際に同じくらい重要なら、同じくらいのSHAP値が割り当てられます。
臨床家へのメッセージ
医療系のデータは、相関する指標の宝庫です。血液データ、重症度スコア、FIM各項目間、認知機能テストのサブスコア——これらを全部モデルに投入しても、SHAP値であれば比較的公平に解釈できます。
「相関しているから除外しなければならない」というプレッシャーから解放され、臨床的に意味のある変数を安心してモデルに投入できる——これがSHAPの実用上の大きな強みのひとつです。
まとめ:Waterfall plotとForce plotで何が変わるか
| Waterfall plot | Force plot | |
| 見た目 | 縦の階段グラフ | 横の押し合いのグラフ |
| SHAP値 | 全く同じ | 全く同じ |
| 強み | 1コマずつ追える・記録に残せる | 1秒で勝敗がわかる・比較に向く |
| 向く場面 | カンファレンス資料・患者説明 | ダッシュボード・スクリーニング |
| 覚え方 | 会計の明細書 | 押し合いのスコアボード |
そして、どちらのグラフを使うときも忘れてはいけないこと:
- ベースラインは「平均予測値」
- ベースライン+SHAP値の合計が予測値
- 分類モデルのSHAP値は確率ではなく対数オッズの世界
- SHAP値が大きい変数が治療ターゲットとは限らない
- SHAP値はモデルの解釈であり、データの真実ではない
SHAP値(waterfall plot/force plot)に関連がある記事

【著者について】
理学療法士(回復期リハビリ病棟 12年以上)
統計検定2級・Python 3エンジニア認定(データ分析)取得。
臨床現場でのデータ活用を目的に統計・機械学習を独学。
FIM退院予測モデルを個人で設計・実装(スタッキングアンサンブル+SHAP)。
強化学習(MuJoCo/Walker2d)や高位頸髄損傷患者向けデバイスの
自作など、臨床課題を技術で解くことに関心を持つ。
医療職向けに統計・データサイエンスをわかりやすく解説するブログ
「Curiosity Creates」を運営中。

コメント