

はじめに
「標準偏差と分散はデータのばらつきの指標」——そんな説明を一度は聞いたことがあると思います。標準偏差や分散について説明してくれる資料はたくさんありますが、それらを見てこんな風に思ったことはありませんか?
- 解説サイトを読んでも何だかすっきりしない
- 論文やデータ分析の結果を見ても直感的にピンとこない
- 教科書の計算式を眺めても、結局何を計算しているのかよく分からない
この記事では、数式を眺めるだけでなく、自分でデータ点を動かせるインタラクティブな図を使いながら、標準偏差と分散の「正体」を体感的につかむことを目指します。数式が苦手でも大丈夫です。まずは手を動かしてみましょう。
この記事では、偏差と標準偏差・分散を取り上げます。それぞれ「言葉でイメージをつかむ → 実際に触って体感する」という流れで理解を深めていきましょう。
実際にスライダを動かして偏差や標準偏差・分散がどのように変化するか、ぜひ確かめてみてください。
データのばらつきって?
データを分析するとき、代表値としてまず登場するのが平均値です。でも、平均値だけでは見えてこない情報があります。
例として、2つのグループの身長データを見てみましょう。
| グループA | グループB | |
| メンバー1 | 165 cm | 190 cm |
| メンバー2 | 155 cm | 135 cm |
| メンバー3 | 163 cm | 165 cm |
| メンバー4 | 157 cm | 150 cm |
| 平均 | 160 cm | 160 cm |
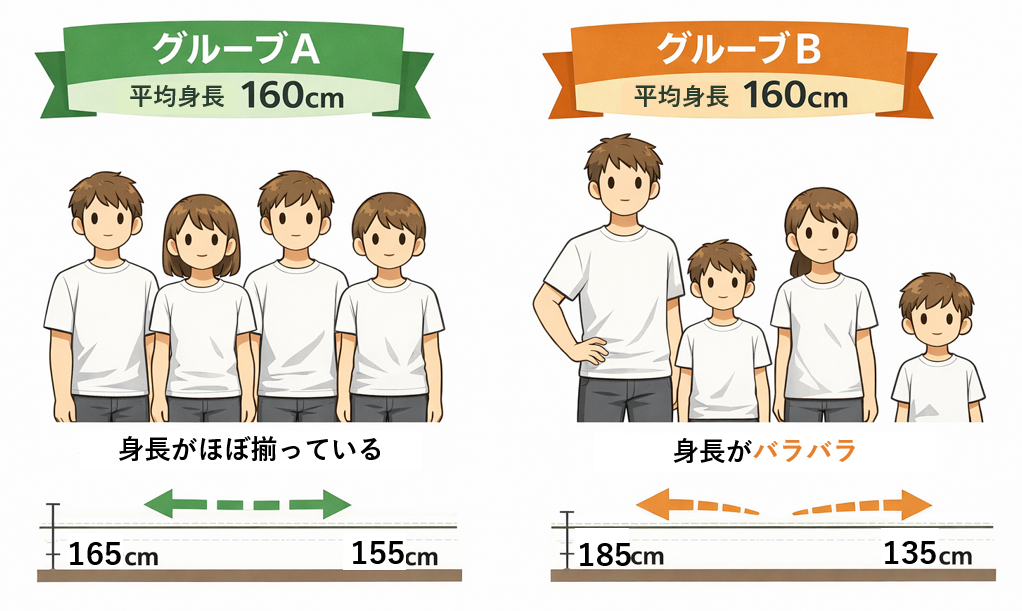
どちらのグループも平均身長は160 cmです。これだけだと似た様なグループかな?と思ってしまいます。でも、実態はかなり違いますよね。
グループAは身長が159〜165 cmとほぼ揃っているのに対して、グループBは135〜185 cmとかなりバラバラです。平均値が同じでも、集団の「様子」は全然違う。このばらつきの大きさを数値で表すのが、標準偏差と分散です。
まず「偏差」ってなに?
標準偏差も分散も、どちらも「偏差」という値から計算されます。偏差とはシンプルに言うと、各データの平均値からのずれのことです。
つまり「それぞれのデータが平均からどれだけ離れているか」を表す距離です。
下のインタラクティブ図で確かめてみましょう。数直線上の丸いデータ点をドラッグして動かしてみてください。オレンジの破線が平均値で、色付きの帯がそれぞれのデータの偏差です。
一つのデータを動かすと平均値も一緒にずれて、他のデータの偏差も連動して変わることが見えるはずです。データは互いに「つながって」いるんですね。
標準偏差と分散を正方形の面積で考える
標準偏差と分散について、まず言葉でイメージをつかんでおきましょう。
各データの偏差を「長さ」として考え、その長さを一辺とする正方形を描いてみます。すると:
- 各正方形の面積 = 偏差²(偏差の二乗)
- 各正方形の合計面積 = 偏差平方和
- 各正方形の平均面積(合計面積をデータ数で割った値) = 分散
- 平均面積の正方形の一辺の長さ = 標準偏差
「それぞれの正方形の面積を平均した正方形の面積」——それが分散です。標準偏差はその正方形の一辺の長さになります。このイメージを頭に入れたまま、次の計算式を見てみましょう。
実際に動かして確かめよう
頭で考えるだけではなかなかピンとこないので、実際に触って確かめましょう。下の図では、数直線上のデータ点を自由にドラッグできます。
いくつか試してみてほしいことがあります。
- データを全部一か所に集める → 標準偏差・分散がゼロに近づく
- データを左右に思い切り広げる → 紫の正方形(分散)がどんどん大きくなる
- 1点だけ極端に離す → その1点が全体の分散を大きく引き上げる(外れ値の影響)
データが平均から離れていくほど、下側の正方形(各偏差²)が大きくなり、それを平均した上側の紫の正方形(分散)も大きくなります。標準偏差はその正方形の一辺の長さです。
※ 一般に統計解析やデータ分析での分散は「データ数 − 1」で割ります(不偏分散)。今回はわかりやすさを優先して、「データ数」で割る標本分散で説明しています。
一応、計算式も確認しておこう
式で見るとこういう形になります。
分散 (σ²) = Σ(各データ − 平均)² ÷ データ数
標準偏差 (σ) = √分散
まあ、文字で書くとなんとなくわかりにくいですよね。先ほどの「正方形の面積の平均、その一辺の長さ」というイメージと照らし合わせると、式の意味が見えてくるはずです。
標準偏差と分散、それぞれのポイント
標準偏差のポイント
① 単位が元データと同じで直感的に解釈しやすい
例えば身長データ(cm)の標準偏差は「cm」の単位で返ってきます。「標準偏差10 cm」なら、データが平均から平均的に10 cm程度ずれている、とざっくりイメージできます。
② 正規分布と組み合わせると強力
データが正規分布に従う場合、次のような推測ができます。
- 平均 ± 1σ の範囲にデータの約68%が入る
- 平均 ± 2σ の範囲にデータの約95%が入る
- 平均 ± 3σ の範囲にデータの約99.7%が入る(68-95-99.7則)
この性質を使えば「このデータはかなりレアな値だ」といった判断ができます。t検定や偏差値もこの考え方がベースです。
分散のポイント
① 直感的にはつかみにくい
分散は偏差を二乗した値の平均なので、単位が元データの「二乗」になります。体重データなら「kg²」。これは直感的にイメージしにくいですよね。だからデータの解釈には標準偏差の方が使われます。
データの特性を見る時に直接分散を確認することは多くありませんが、機械学習モデルの誤差指標であるMSE(平均二乗誤差)や分散分析などでは直接分散をチェックすることもあります。
② でも計算上はとても都合がいい
分散が重宝されるのは、統計モデルや機械学習の計算に入れたときです。数学的な扱いやすさ(後述)があるためです。t検定のような基礎的な統計分析から、機械学習・ディープラーニングといった高度な分析手法まで分散は中心的な役割を担います。
【補足】なぜ絶対値ではなく二乗するのか?
「偏差の大きさを表したいなら、絶対値でもよくない?」という疑問、自然だと思います。
実は絶対値を使う指標(平均絶対偏差:MAD)も存在します。でも分散(二乗)が主流な理由は数学的な扱いやすさにあります。
- 微分可能:最適化計算(勾配降下法など)がそのまま使える
- 加法性:独立な変数の分散は足し算できる(Var(X+Y) = Var(X) + Var(Y))
これが、機械学習・ベイズ統計・信号処理などあらゆる分野で分散が使われる理由です。
まとめと次のステップ
今回の内容を整理すると、こういう流れでした。
偏差(平均値からのずれ)→ 偏差平方和(面積の合計)→ 分散(面積の平均)→ 標準偏差(一辺の長さ)
数式よりも先に「正方形の面積」のイメージをつかんでおくと、式の意味がすっと入ってきます。インタラクティブな図で手を動かしたことで、より直感的に理解できたのではないでしょうか。
標準偏差・分散に関連する記事
【図解】標準偏差と標準誤差の違いをわかりやすく解説
【図解】標準偏差と分散の違い
JASPで基礎統計量+グラフ作成
Excelで基礎統計量
95%信頼区間とは?
正規分布とは?

【著者について】
理学療法士(回復期リハビリ病棟 12年以上)
統計検定2級・Python 3エンジニア認定(データ分析)取得。
臨床現場でのデータ活用を目的に統計・機械学習を独学。
FIM退院予測モデルを個人で設計・実装(スタッキングアンサンブル+SHAP)。
強化学習(MuJoCo/Walker2d)や高位頸髄損傷患者向けデバイスの
自作など、臨床課題を技術で解くことに関心を持つ。
医療職向けに統計・データサイエンスをわかりやすく解説するブログ
「Curiosity Creates」を運営中。


コメント