

相関分析と回帰分析は、文献や研究発表などでよく見かける一般的な解析手法です。
しかし、その違いは?と聞かれると意外と答えられないことが多いのではないのでしょうか?
実際この二つはデータの組み合わせから、特徴を抽出するという点でとても似ています。
単純な二つのデータのペアで分析した結果をグラフにすると以下のような具合です。

どちらも同じように見えますね。では、見た目は同じ二つのグラフが表現するものにはどんな違いがあるのでしょうか?
この記事では相関分析と回帰分析の違いを、用途・結果の出力・サンプル数と精度の関係・使用例・共通の弱点について紹介していきます。
相関分析とは
相関分析とは、2つのデータ(変数)の間に「一方が増えると、もう一方はどうなるか」という関係性や、その強さを数値化(相関係数)して調べる統計的手法です。
重要な特徴は、どちらが原因でどちらが結果かを問わない点です。「入院時FIMと退院時FIMは関係があるか?」という問いに答えることはできますが、「どちらが原因か」は相関分析の範囲外です。
相関係数(r)の読み方
rは −1 〜 +1 の範囲をとり、0から離れるほど関係が強くなります。
| rの値の目安 | 関係の強さ | 臨床でのイメージ |
| ±0.7 以上 | 強い相関 | ほぼ直線上に並ぶ |
| ±0.4 〜 0.7 | 中程度の相関 | ある程度のまとまり |
| ±0.4 未満 | 弱い〜ほぼなし | ばらつきが大きい |
⚠️ 注意:サンプルサイズが大きいと、臨床的に意味のない弱い相関(r = 0.2 程度)でも p < 0.05 になることがあります。p値だけでなくrの大きさ自体を必ず確認しましょう。この点は「サンプルサイズと分析精度」のセクションで詳しく説明します。
回帰分析とは
回帰分析とは、あるデータが、他のデータからどのような影響を受けているかを分析する統計手法です。分析者があらかじめ『XでYを推測する』という方向性を設定し、その影響の大きさの推定や予測を行います。
各指標の意味は以下の通りです。
| 指標 | 意味 |
| β(回帰係数) | Xが1増えたとき、Yが平均的にどれぐらい変化するかを表す。最も重要な指標。 |
| 切片 | Xが0のときのYの予測値。 |
| R²(決定係数) | X(独立変数)でYをどれぐらいうまく推測できているかを0〜1で表す。1に近いほど良い。 |
相関分析と回帰分析の違い
まずはイメージをつかむために、分析の具体例とえられる結論を考えてみます。
入院時の生活自立度(FIM)と退院時の生活自立度(FIM)について分析する、という事例を取り上げます。それぞれの分析手法を使うことで、どんな分析結果が得られるでしょうか?
【相関分析】
入院時fimと退院時fimには強い関連があり、片方が上がるともう片方も上がる。入院時のFIMが退院時のFIMに影響しているのか、又はその逆なのかということは問わない。
【回帰分析】
入院時fimが1上がると、退院時fimは0.72上がる。
退院時fimは(入院時fim)×0.72 + 18.3という計算式で推測できる。
大まかにいうと、相関分析と回帰分析で得られる結果にはこのような違いがあります。
相関分析は関連性だけがわかり、回帰分析では関係性を分析して推測ができるようになります。
大枠がわかったところで、ここから先は具体的な違いにどのような点があるのか見ていきましょう。
※ここで出している数値例は説明のため、筆者が記事作成中に適当に決めたものです。上記の数値は医学的根拠や疾患の実態を反映したものではありません。
① 用途の違い:「関係を知りたい」か「予測・因果関係を知りたい」か
最も根本的な違いは目的です。相関分析は2変数の間に関係があるかどうかを調べる探索的な分析です。回帰分析はXがYに与える影響の大きさを定量化し、予測や因果の検討に使います。
| 相関分析 | 回帰分析 | |
| 目的 | 関係の強さと方向を知る | 影響の大きさを定量化・予測する |
| 因果の方向 | 問わない(双方向) | 設定する(XがYに影響) |
| 主な指標 | r(相関係数)、p値 | β(回帰係数)、切片、R²、p値 |
| 医療での用途 | 関連因子の探索・スクリーニング | 予測モデル構築・交絡を調整した上での関連 |
② 同じデータで両方やると何が違う?実例で確認
具体的なイメージを掴むために、「入院時FIM → 退院時FIM」という臨床でよく使われるデータを例に、同じデータで両方の分析を実行した結果を比較してみます。
| 相関分析の結果 | 回帰分析の結果 | |
| 出力される数値 | r = 0.65、p < 0.01 | β = 0.72、切片 = 18.3、R² = 0.42、p < 0.01 |
| わかること | 入院時FIMと退院時FIMには中程度の正の相関がある。つまり、二つには関連があり、片方が増えればもう片方も増える。(どちらがどちらに影響を与えているのかは問わない。) | 入院時FIMが1点高いと、退院時FIMは平均0.72点高くなる |
| 答えられる問い | 「関係があるか?」 | 「どのくらい影響するか?」 「退院時FIMを予測できるか?」 「入院時FIMと退院時FIMには因果関係があるか?」(独立変数が複数の場合) |
ポイント:相関分析では「関係がある・ない」と「その強さ」しかわかりません。「1点違うとどれくらい変わるか」という具体的な数値を出したいときは回帰分析が必要です。
※ここで出している数値例は説明のため、筆者が記事作成中に適当に決めたものです。上記の数値は医学的根拠や疾患の実態を反映したものではありません。
③ サンプルサイズと分析精度の違い
どちらの手法も、サンプルサイズが小さいと推定値が不安定になります。ただし、その不安定さが実務にどう影響するかは、二つの手法で異なります。
下のグラフは、サンプル数を変えながら繰り返しデータを抽出・分析したときの結果のばらつきを示したものです。相関係数(r)と回帰係数(β)は、どちらもサンプルが増えるにつれて同じように安定していきます。
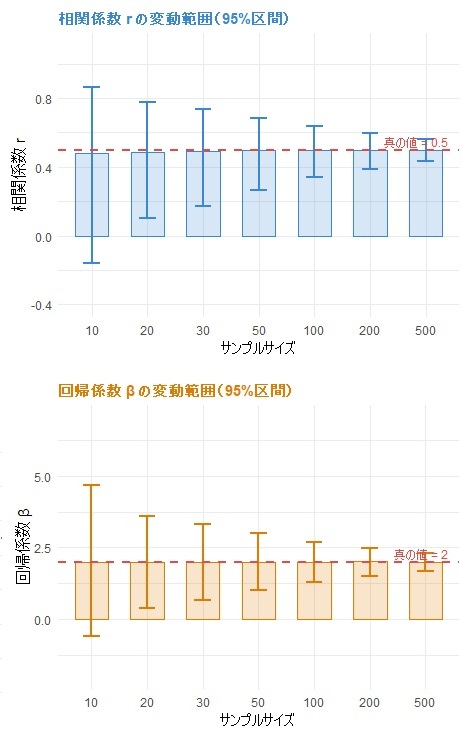
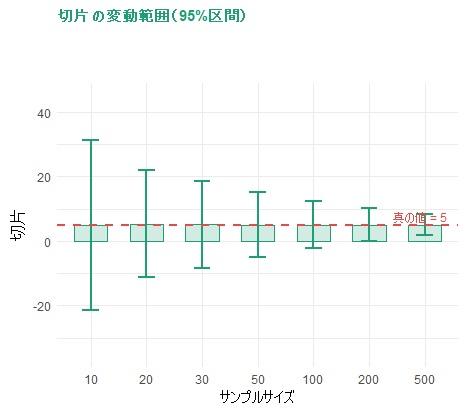
| n | r の95%区間 | β の95%区間 | 切片の95%区間 |
| 10 | −0.13 〜 0.87(幅1.00) | −0.53 〜 4.64(幅5.18) | −21.8 〜 30.5(幅52.3) |
| 30 | 0.18 〜 0.73(幅0.55) | 0.69 〜 3.30(幅2.61) | −8.0 〜 18.3(幅26.3) |
| 100 | 0.34 〜 0.64(幅0.30) | 1.31 〜 2.70(幅1.39) | −2.1 〜 12.0(幅14.1) |
| 500 | 0.43 〜 0.57(幅0.14) | 1.70 〜 2.31(幅0.61) | 1.8 〜 8.1(幅6.3) |
数字だけ見ると、二つの手法に大きな差はないように思えます。しかし回帰分析は具体的な予測値を出すために使うことが多く、そこにサンプル不足の影響が顕著に現れます。
試しに計算してみましょう。今回のサンプルデータは「β=2、切片=5」という設定で生成したため、X=10のときの正しい予測値は
Y=2×10+5=15
です。ところがサンプル数が30のとき、βは0.69〜3.30、切片は−8.0〜18.3の範囲でばらつくことが十分あり得ます。最も外れた組み合わせで計算してみると
Y=3.3×10+30.5=63.8
となり、本来の15から大きく乖離した予測値が出てしまいます。
相関分析なら「関連がある・なし」という結論だけを出せばよいため、多少の係数のぶれは実害になりにくいです。一方、回帰分析は予測値という具体的な数値を使う場面が多いため、サンプル不足の影響が結果に直接響きます。サンプル数が10〜30程度では、回帰式による予測は実用に耐えないと考えておくのが無難です。
④ 変数が増えたときは?
複数の変数を扱いたい場合は、分析をする文脈にもよりますが以下のような方法がとられることが多いです。
相関行列・散布図行列:複数の変数すべての組み合わせを総当たりで相関係数を算出・可視化する。関連がありそうな変数のあたりをつける段階に有効。
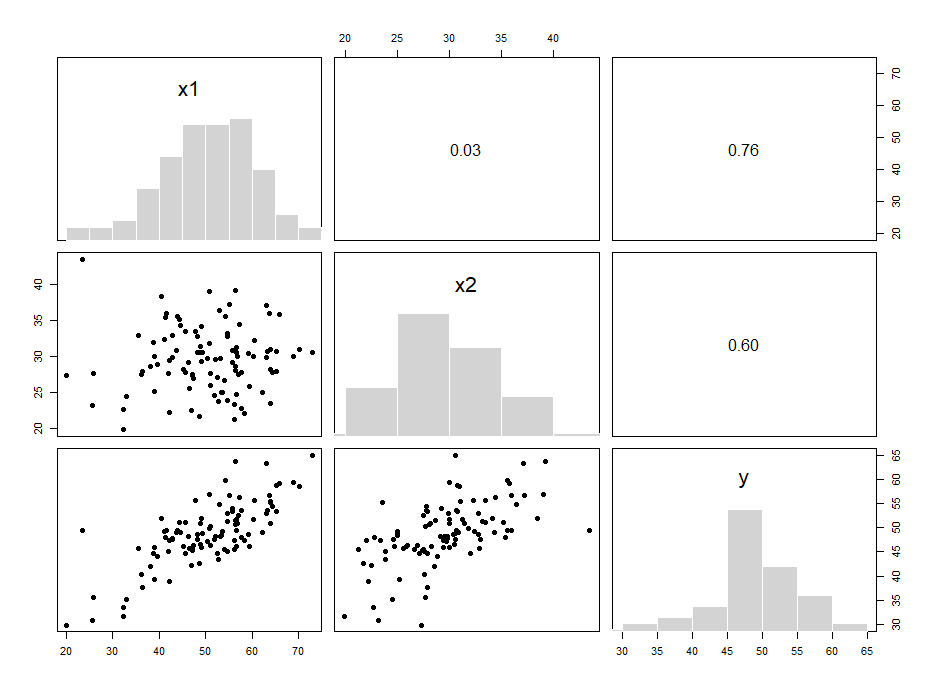
重回帰分析:複数の説明変数から1つの目的変数を予測する。「他の変数を考慮した上で、この変数は独立して影響するか?」という問いに答えられる。
下のグラフは二つのデータ(X1,X2)から一つのデータ(Y)を予測する、という状況で分析を行いそれを立体的に表現したものです。データの分布にうまく沿うように、平面が描画されています。(マウスでぐりぐり動かせるようになっています。)この平面が重回帰分析によって求められた、X1,X2とYの関係です。
どんな状況でどちらを選ぶか?(臨床例で解説)
シナリオ① データ間の関係性を幅広く探したい
例:退院時FIMに関連する要因がまだわからないとき
年齢・入院時FIM・認知機能・疾患重症度など多数の変数と退院時FIMとの相関係数を一度に算出し、どの変数と関係が強いかのあたりをつける。この段階では方向性の探索が目的なので、相関分析が適している。
シナリオ② あるデータを数値で予測したい
例:入院時FIM・年齢から退院時FIMを予測したい
「入院時FIMが〇〇点の患者は、退院時に何点になりそうか」という具体的な予測値を出したい場合は回帰分析(重回帰分析)を使う。βが「1点違うとどれだけ変わるか」を直接表すため、予測や目標設定に活用できる。
シナリオ③ ある要因が独立して影響するか検証したい
例:脳卒中後うつ病が退院時ADLに独立して影響するか?
年齢や入院時ADLなどの影響を除いた上で、うつ病の有無が退院時ADLに影響するかを調べたいときは重回帰分析を使う。他の要因を「コントロール」しながら特定の変数の影響を取り出せる点が回帰分析の強みです。
両手法に共通する注意点
外れ値に弱い
どちらの手法も外れ値(通常とは挙動の異なる症例)の影響を強く受けます。1〜2例の特異な症例が加わるだけで、相関係数や回帰係数が大きく変わることがあります。分析前に必ず散布図を確認し、外れ値がないかをチェックしてください。
ちょっとした実験ができるシミュレーターを用意しました。
グラフ上をクリックすると、クリックした場所に新しいデータ点が追加されます。新しく追加されたデータも利用してrやβが再計算されます。
線の近くであれば、rやβ・切片はあまり変わりません。しかし、外れ値として線から大きく外れた部分(グラフの右下の角、等)に点を追加すると、推定値が大きく変動するはずです。
👆 グラフをクリックして外れ値を追加してみよう
散布図を必ず確認する:相関係数やβだけを見ても、データの全体像はわかりません。r = 0.5 でも、外れ値が1点あるだけでその数値になっている場合があります。数値の前に必ず散布図を目で見ることが鉄則です。
サンプルサイズが少ないと精度が大きく下がる
n=20程度では検出力が60%台に留まり、真の関係があっても有意にならないケースが多くなります。医療研究でよく遭遇する「n=20〜30の後ろ向き研究」では、有意でなかった結果を「関係がない」と結論づけることには慎重さが必要です。
目安として、相関・単回帰ではn=50以上、重回帰ではさらに多くのサンプルが推奨されます。
まとめ
| 相関分析 | 回帰分析 | |
| 目的 | 関係性の探索 | 予測・因果の定量化 |
| 主な指標 | r、p値 | β、切片、R²、p値 |
| 答えられる問い | 「関係があるか?」 | 「どのくらい変化するか?」 |
| 変数が増えたら | 相関行列 | 重回帰分析 |
| 共通の注意 | 外れ値・サンプルサイズの影響を受ける | 外れ値・サンプルサイズの影響を受ける。予測などでは悪影響が目立ちやすい。 |
相関分析と回帰分析は、どちらも変数の関係を扱いますが、目的がまったく異なる手法です。「関係があるかどうかを探る」段階では相関分析を、「具体的な影響の大きさを知る・予測する」段階では回帰分析を選ぶ、という基準で使い分けてください。
どちらの手法も、外れ値の確認と十分なサンプルサイズの確保が信頼できる結果を得るための前提条件です。散布図の確認を怠らず、サンプルサイズには余裕を持った研究設計を心がけましょう。
相関・回帰分析に関係する記事
JASPでのピアソンの相関分析のやり方
JASPでの重回帰分析のやり方
JASPでのロジスティック回帰分析のやり方
多重共線性の回避方法5選


コメント