

はじめに
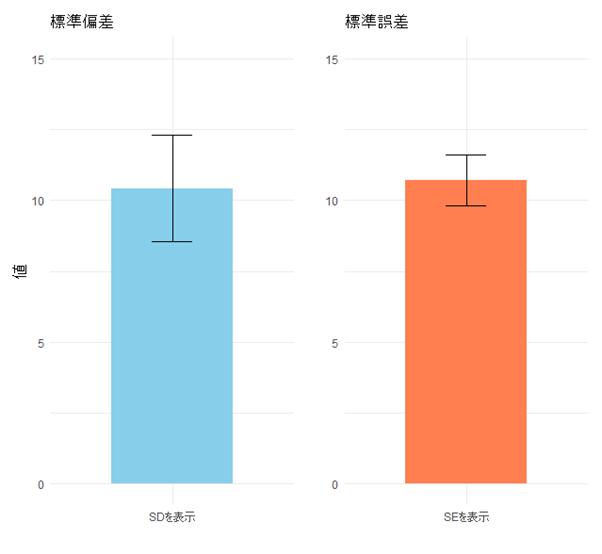
論文などでよく見るエラーバー。例えば下のようなグラフです。
説明書きを見ると「標準誤差」や「標準偏差」といった言葉が書かれているが、正直違いがわからない——そんな経験はありませんか?
この記事ではまず簡単なゲームで、「一部から全体を推測する経験」をしてみます。その体験を振り返りながら、標準偏差と標準誤差の違いを体感レベルで理解することを目指します。
あなたならいくつと読む?年齢当てゲーム
はじめに標準偏差と標準誤差の理解の土台となる「データから”真の値”を推測する」感覚を、簡単なゲームで体験してみましょう。
次のような場面を想像してみてください。
あるお店では、プロモーションのためにお客さんの平均年齢を知りたいと思っています。毎日1000人以上来店しますが、全員に年齢を聞くのは現実的ではありません。 5人に聞いた場合と、100人に聞いた場合——それぞれで来店客全体の平均年齢を推測してみましょう。
まずは実際に試してみてください。
ゲームの目的と設定
冒頭のゲームでは、来店客という大きな集団から抜き出したサンプル(実際聞いた年齢)で、集団全体の平均を推測してみました。
ゲーム中で2つの質問に答えてもらいました。実は、それぞれがこの記事で解説する二つの重要な概念に対応しています。
| ゲームの質問 | 選択肢 | 対応する統計概念 |
| この推測、どのぐらい自信がありますか? | 全然自信なし〜かなり自信あり | 標準誤差(SE) |
| データのばらつきはどう見えましたか? | 小さい・中くらい・大きい | 標準偏差(SD) |
母集団と標本の補足
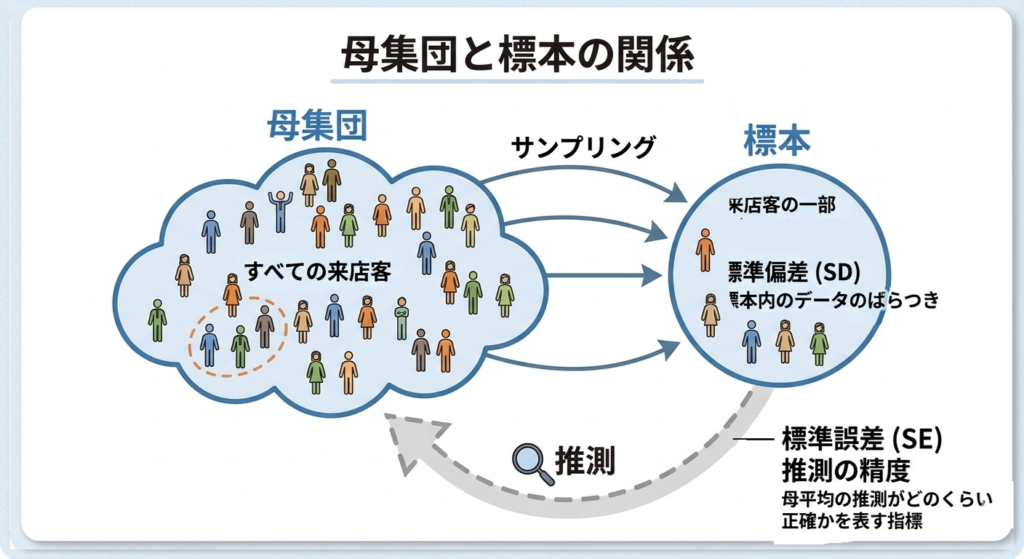
ゲームの文脈で簡単に補足します。ゲームに登場した年齢データは「標本」です。——つまりすべての来店客(母集団)から一部を取り出したものです。
標本から母集団の平均を推測するとき、どのくらい正確に推測できるか、その精度を表す指標が標準誤差(SE)です。一方、標本内のデータが互いにどのくらいばらついているかを表すのが標準偏差(SD)です。
重要なのは、たまたま選び出された人の年齢平均が、必ずしも集団全体の平均とは一致しないということです。
選び出される人は「たまたま」選ばれるだけなので、偶然若い人ばかりが選ばれることもあり得ます。特に実際に聞いた人数が少ないときは、偶然による偏りの影響を受けやすくなります。
画像はgeminiで作成
標準偏差(SD)・標準誤差(SE)の定義
では、標準偏差と標準誤差の具体的な定義を見てみましょう。
標準偏差(SD):データのばらつきを表す
標準偏差は、個々のデータが平均からどのくらい離れているかを数値化したものです。
ゲームで「ばらつきが大きい」と感じた状態がSDの大きい状態、「ばらつきが小さい」と感じた状態が標準偏差の小さい状態に対応します。
計算式(触れる程度):
SD = √( Σ(xᵢ − x̄)² / (n−1) )
一応数式も出してみましたが、大事なのは標準偏差とは取得できたデータそのもののばらつき具合だ、という点です。そこが抑えられていればOKです。
標準誤差(SE):平均の推定精度を表す
標準誤差の理解で大事なポイントは二つあります。
・標準誤差は「サンプルから計算した平均が、集団全体の本当の平均からどのくらいばらつくかを示した指標」である
・サンプルの数が増えるほど標準誤差は小さくなる(推定精度が上がる)
一つ目:標準誤差は推定精度を表す
冒頭のゲームを例にします。N=5よりもN=100のほうが、推測に自信を持ちやすかったのではないでしょうか。ゲームで「自信がない」と感じた状態がSEの大きい状態、「かなり自信あり」がSEの小さい状態に対応します。
標準誤差が小さいほど、サンプルから計算した平均が来店客全体の平均に近い——つまり推測が外れにくいことを意味します。これは信頼区間の理解でも重要になるポイントです。
二つ目:nが増えるとSEは小さくなる
計算式を見るとその理由が直感的にわかります。
SE = SD / √n
データのばらつき(SD)が同じでも、サンプル数nが増えるほどSEは小さくなります。
次の触れる図で実際に動かして確かめてみましょう。
触れる図:nを動かしてSEの変化を確かめよう
触れる図
以下の触れる図で実際に操作してみましょう。
- スライダーを動かして「1回サンプリング」を何度か押してみる
- 標準偏差の数値と標準誤差の数値を見比べる
- nを小さくしたとき・大きくしたときで標準誤差がどう変わるか確認する
操作すると分かること
nを変えながら繰り返しサンプリングすると、次のことが見えてきます。
- 母集団の分散が大きくなると、標準偏差も標準誤差も大きくなる。
- 標準偏差は、nを変えても大きく変わらない(データのばらつきは標本数に依存しない)
- 標準誤差は、nが増えるほど一貫して小さくなっていく
- 同じ母集団・同じ標準偏差でも、標準誤差はnを増やすことで推定精度を上げられる
これが「標準偏差はばらつき、標準誤差は推定精度」という区別の実体です。
エラーバーの使い分け
SDエラーバー vs SEエラーバー:見た目の違い
論文や報告書のグラフに描かれるエラーバーには、標準偏差を使ったものと標準誤差を使ったものがあります。ちなみにエラーバーとは論文などでよく見かけるこういうものです。
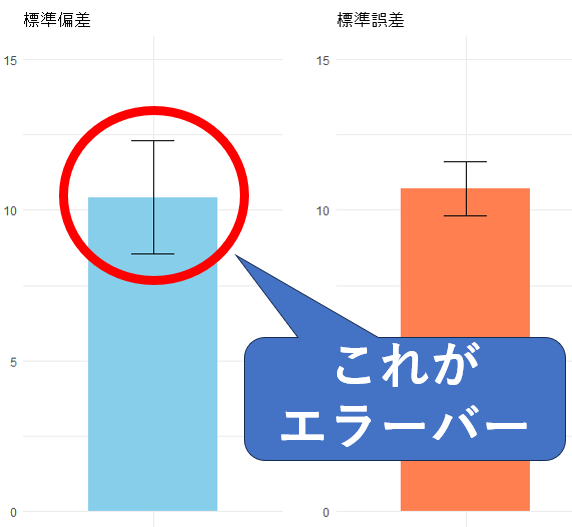
標準偏差と標準誤差の関係から、標準誤差のエラーバーは標準偏差のものより必ず短くなります。nが大きいほどその差は顕著です。
どちらを使うべきか
標準偏差と標準誤差では、読み取れる内容や注意点が違います。
| SDバーを見たとき | SEバーを見たとき | |
| 何がわかるか | この集団のデータのばらつき | 平均値の推定精度 |
| 読むときの問い | 「研究対象は、自分の担当患者と似た患者層か?」 | 「この平均値はどのくらい信頼できるか?」 |
| 注意点 | 個人差の議論に使われているか確認 | nが小さくないか確認 |
この記事の冒頭では、来店客全体から数名を選んで年齢を確認しました。臨床研究でも同様に、研究対象となったサンプルのばらつきを示すために標準偏差が使われています。
論文で標準偏差やSDのエラーバーの値を見たとき、それは「この研究に参加した人たちの多様性」を読み取るための情報です。
たとえば、20〜80歳まで幅広い年齢層が含まれた研究であれば標準偏差は大きくなります。「これだけ多様な属性の患者で効果が出ているなら、この介入の効果は安定していそうだ」という判断材料になります。逆に、60〜80歳に限定された研究で標準偏差が小さければ、「高齢者に特化した研究で、今の担当症例にぴったりだ。でも若い患者さんが来た時には、同じ効果が出るか注意が必要だな。」と対象集団の絞り込みを確認できます。
一方、標準誤差は「この論文の平均値がどのくらい信頼できるか」を読み取るための情報です。
標準誤差が小さければ推定精度が高く、報告されている平均値の信頼性が高いと判断できます。標準誤差が大きければ推定精度が低めであり、「この結果だけで結論付けず、他の文献も確認しよう」という読み方が適切です。
臨床・論文読解での実例
標準誤差が使われやすい場面と理由
標準誤差は標準偏差より常に小さい値になるため、エラーバーが短く見えます。これは推定精度を示す文脈では正しい使い方ですが、文脈を確認せずに読むと誤解を招くケースがあります。
標準誤差の意図的・無意識的な誤用パターン
パターン1:個人差を見せたい場面でSEを使う
例:「リハビリ後の歩行速度の変化」を示すグラフで、個々の患者がどれだけ改善したかのばらつきを伝えたい場面にもかかわらず、SEバーを使っているケース。
SEバーは平均の精度を示すものであり、個人差の大きさは伝わりません。読者に「みんな同じくらい改善した」という誤った印象を与えます。
パターン2:nが小さいのにSEを使う
SE = SD / √n のため、nが小さいと標準誤差は標準偏差とあまり変わりません。しかしnが小さい研究で標準誤差を使うと、精度が高いように見せかける効果が生まれます。
パターン3:エラーバーの種類を明記しない
論文・報告書でエラーバーの種類(標準偏差/標準誤差/95%CI)が図の説明に書かれていないケースがあります。種類によってバーの長さが大きく変わるため、必ず確認する習慣が重要です。
論文を読むときのチェックポイント
- 図の凡例または本文でエラーバーの種類(SD/SE)を確認する
- SEバーが使われているとき、nはいくつか確認する
- 個人差・集団内ばらつきを議論する文脈でSEバーが使われていないか注意する
- 比較グラフでバーが重なっていないからといって、即座に有意差ありとは判断しない
臨床場面での具体例
変形性膝関節症患者20名に対する筋力トレーニング介入研究を例にとります。
介入前後の大腿四頭筋筋力(N/kg)の平均値をグラフで示す場合——
- SDバーを使う場合:患者間のばらつきの大きさが伝わる。「効果にムラがある患者集団」であることが視覚的に明確
- SEバーを使う場合:介入効果の推定精度が伝わる。「平均として効果があったのか?」に興味がある場合に適切
どちらが正しいかではなく、「何に興味があるか?」で選ぶことが重要です。ただし、SEバーを使いながら「個人差」を議論している場合は要注意です。
まとめ
- 標準偏差はデータのばらつき。nを変えても大きく変わらない
- 標準誤差は平均の推定精度。nが増えるほど小さくなる(SE = SD / √n)
- エラーバーの種類は論文で必ず確認する
- 標準誤差は常に標準偏差より小さくなるため、誤用・意図的な使用に注意
標準偏差・分散に関連する記事
【図解】標準偏差と標準誤差の違いをわかりやすく解説
【図解】標準偏差と分散の違い
JASPで基礎統計量+グラフ作成
Excelで基礎統計量
95%信頼区間とは?

【著者について】
理学療法士(回復期リハビリ病棟 12年以上)
統計検定2級・Python 3エンジニア認定(データ分析)取得。
臨床現場でのデータ活用を目的に統計・機械学習を独学。
FIM退院予測モデルを個人で設計・実装(スタッキングアンサンブル+SHAP)。
強化学習(MuJoCo/Walker2d)や高位頸髄損傷患者向けデバイスの
自作など、臨床課題を技術で解くことに関心を持つ。
医療職向けに統計・データサイエンスをわかりやすく解説するブログ
「Curiosity Creates」を運営中。


コメント