

はじめに
統計を勉強していると、いたるところで正規分布が登場します。
t検定の前提、信頼区間の計算、回帰分析の誤差……統計の教科書を開くたびに「正規分布に従うと仮定して」という一文が出てきます。でも、なぜこれほどまでに正規分布が特別扱いされるのでしょうか?
この記事では、正規分布の基本的な見た目や式から始まり、「正規分布を仮定すると何がうれしいのか」「現実のデータはどうなのか」「統計解析ではどんなところで正規分布が出てくるのか」まで、初心者の方にもわかりやすく読んでもらえるようにていねいに解説します。
正規分布とは?「釣り鐘型」の分布
正規分布(normal distribution)とは、平均値を中心に左右対称な釣り鐘型をした確率分布のことです。ガウス分布(Gaussian distribution)とも呼ばれます。
身長、体重、血圧、測定誤差など、自然界や生体計測で得られるデータの多くが、この正規分布に近い形をしています。
確率密度関数
正規分布の形は、次の式(確率密度関数)で表されます。

なんだかすごく難しいそうですよね。でも、この式の中で大事なのは2か所だけです。
ポイントはたった2つのパラメータ(μとσ)だけでこの式が決まるという点です。次のセクションで直感的に説明します。
形を決める2つのパラメータ:μ(平均)とσ(標準偏差)
正規分布の形は、μ(ミュー) と σ(シグマ) という2つのパラメータだけで完全に決まります。
μ(平均):分布の「位置」を決める
μは分布全体の「中心がどこにあるか」を決めます。μを大きくすると分布が右にスライドし、小さくすると左にスライドします。形(広がり方)は変わりません。
たとえば、日本人成人男性の身長の平均が171cmであれば、μ ≈ 171 です。
σ(標準偏差):分布の「広がり」を決める
σは分布の「散らばり具合」を決めます。σが小さいと分布は鋭く尖り、σが大きいとなだらかに広がります。
σが小さい → データが平均の近くに集まっている(個人差が小さい) σが大きい → データが平均から広く散らばっている(個人差が大きい)
【インタラクティブ】μとσを動かしてみよう
スライダーを動かすと、μが変わると山の位置が、σが変わると山の高さと幅が変化するのがよくわかります。
なぜパラメータが2つだけでいいのか?
これが正規分布の最大の強みのひとつです。現実の集団を調べる研究を考えてみましょう。もし分布の形をまったく仮定しないと、集団の確率的な特徴を表すために膨大なデータが必要になり、研究のたびに確率密度関数を新たに考案しなければなりません。
正規分布を仮定すれば、数十件のデータがあればμとσの2つを推定するだけで母集団全体の特徴を記述できます。これは計算・解釈・コミュニケーションのすべてにおいて強力なメリットです。
正規分布を仮定すると何が良いのか?
① SD(標準偏差)だけで割合がわかる:68–95–99.7則
正規分布には非常に便利な性質があります。平均からどの範囲にどれだけのデータが含まれるかが、標準偏差の倍数で決まるのです。
| 範囲 | 含まれるデータの割合 |
| μ ± 1σ | 約68.3% |
| μ ± 2σ | 約95.5% |
| μ ± 3σ | 約99.7% |
これを「68–95–99.7則」または「経験則(empirical rule)」と呼びます。
【インタラクティブ】68–95–99.7則を確認しよう
(normal_dist_68_95_997.html)
臨床での活用例
身長の平均が170cm、標準偏差が6cmの集団を考えます。
- μ ± 1σ = 164〜176cm → 約68%の人が含まれる
- μ ± 2σ = 158〜182cm → 約95%の人が含まれる
- μ ± 3σ = 152〜188cm → 約99.7%の人が含まれる
このルールを知っていると、「この患者さんの値は平均から+2SD離れている=上位2.5%に相当する」という判断が素早くできます。
② 少ないパラメータで母集団を推定できる
先ほど触れたように、正規分布を仮定することでμとσの2つを推定するだけで済みます。これにより、t検定・信頼区間・回帰分析などの強力な統計手法が使えるようになります。
標準正規分布と標準化
正規分布の応用を理解するうえで欠かせないのが標準正規分布(standard normal distribution) と 標準化(z変換)です。
標準化とは
任意の正規分布 N(μ, σ²) に従うデータxを、次の式で変換します。
$$ z = \frac{x – \mu}{\sigma} $$
この変換を「z変換」または「標準化」と呼びます。変換後のzは 平均0、標準偏差1 の標準正規分布 N(0, 1) に従います。
なぜ標準化が便利なのか?
理由①:確率の計算が1種類の表で済む
正規分布はμとσの組み合わせが無限にあります。もしそれぞれの組み合わせに対して確率表(正規分布表)を用意しようとすると、膨大な量が必要になります。
標準化を使えば、どんな正規分布でも標準正規分布に変換できるため、確率表は1枚で済みます。偏差値や臨床検査の基準値がz変換を基礎にしているのはこのためです。
理由②:異なるスケールの比較ができる
「身長と体重のどちらが平均からより外れているか」は、単位が違うため直接比較できません。しかし標準化後なら、同じ「標準偏差何個分」という尺度で比較できます。
理由③:ディープラーニングモデルで、学習を効率化できる。
医療分野でも利用が進められているディープラーニングモデルでは、各変数間の関連を自動的に学習して予測モデルを構築することができます。ただ、データの量によっては学習に非常に時間がかかります。このとき、データを標準化しておくとモデルがデータを学習しやすくなり、学習時間の短縮や精度向上につながります。
現実のデータは正規分布ではないことも多い
ここまで正規分布の有用性を説明してきましたが、現実はそう単純ではありません。
よくある逸脱のパターン
天井効果・床効果
臨床上の評価スケールでよく出会う問題です。たとえば、入院初日のFIM(機能的自立度評価)が軽症患者ばかりで構成されたデータでは、得点が最高値に張り付いてしまい(天井効果)、正規分布から大きく外れます。
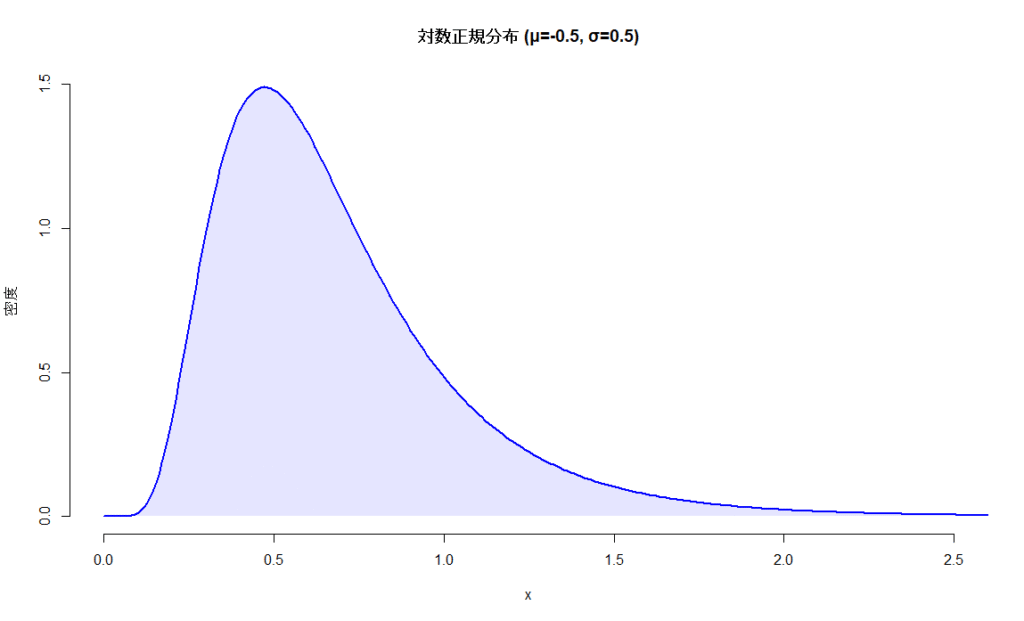
右に裾が長い分布(右歪み)
入院日数・医療費・反応時間などは、多くのデータが小さい値に集まり、一部に非常に大きな値が混じります。こうしたデータは正規分布ではなく対数正規分布に近いことが多いです。例えばこんなデータです。
0か1の二値データ
「成功/失敗」「転倒あり/なし」「再入院あり/なし」などの二値アウトカムは、正規分布ではなく二項分布でモデル化する必要があります。例えばこんなデータです。
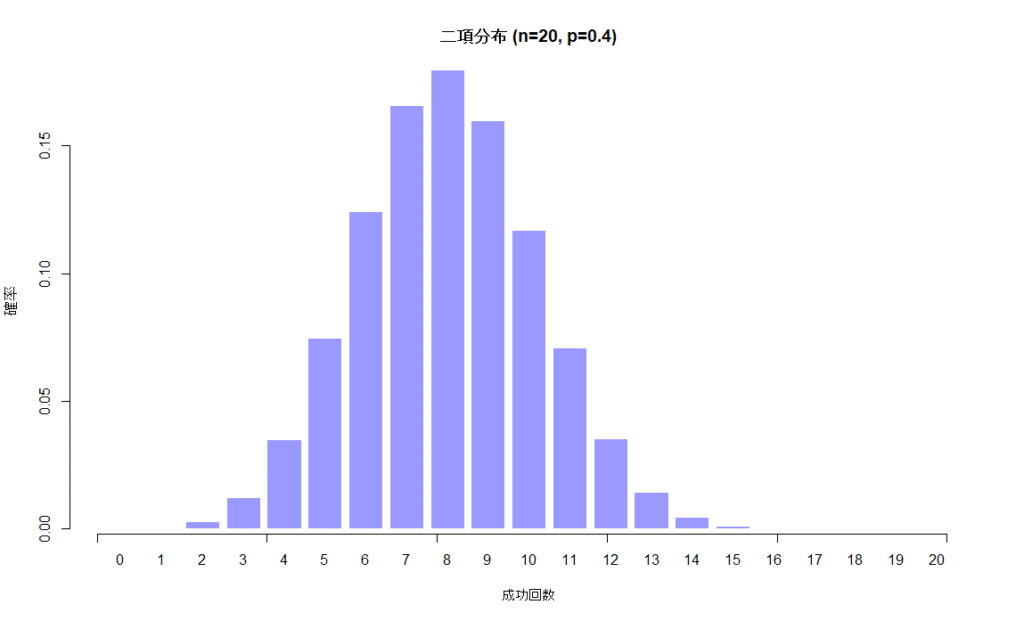
ぱっと見は「え、正規分布じゃないの?」と思うかもしれません。しかし、二項分布では再入院した/しないといった二者択一の現象を扱います。「2.7回再入院した」といったことは起こり得ません。
このような小数点以下がなく数直線上でとびとびの値をとるデータを離散値といいます。このようなデータを正規分布とするのは不適切で、二項分布として扱います。
対処法の一覧
| データの特徴 | 対応する分布 | 主な対処法 |
| 0以上で右裾が長い | 対数正規分布 | 対数変換、ガンマ回帰 |
| 0/1の二値 | 二項分布 | ロジスティック回帰 |
| カウントデータ(発生回数) | ポアソン分布 | ポアソン回帰 |
| 天井・床効果あり | 打ち切り分布 | Tobitモデル、順序回帰 |
| 過分散なカウントデータ | 負の二項分布 | 負の二項回帰、GLMM |
| 繰り返し測定・階層データ | 混合分布 | 線形混合モデル、GLMM |
これらは一般化線形モデル(GLM)や一般化線形混合モデル(GLMM)という枠組みで統一的に扱うことができます。
実際には正規分布を前提にできることも多い:中心極限定理との関係
「でも、自分のデータは正規分布じゃないかもしれない……」と心配になった方も多いと思います。実は、データ自体が正規分布でなくても、正規分布を前提にした検定が使えることはよくあります。
その鍵が**中心極限定理(Central Limit Theorem)**です。
中心極限定理によれば、元のデータの分布によらず、サンプルサイズが十分に大きければ、標本平均の分布は正規分布に近づきます。
つまり、個々のデータが正規分布に従わなくても、サンプルサイズが十分ならt検定や回帰分析などの手法はおおむね有効に機能します。
t検定を例に挙げると一般的には n ≥ 30 程度が目安とされていますが、データの歪みが大きい場合はもっと大きなサンプルが必要なこともあります。
また、中には正規分布であることの仮定が重要な統計手法もあります。そのような検定手法を使用する場合は、事前に正規性の確認を行う必要があります。
中心極限定理について詳しく知りたい方はこちらの記事も合わせてご覧ください。
正規分布が登場する主な統計手法
最後に、臨床研究でよく使われる統計手法において、正規分布がどのように登場するかを整理します。
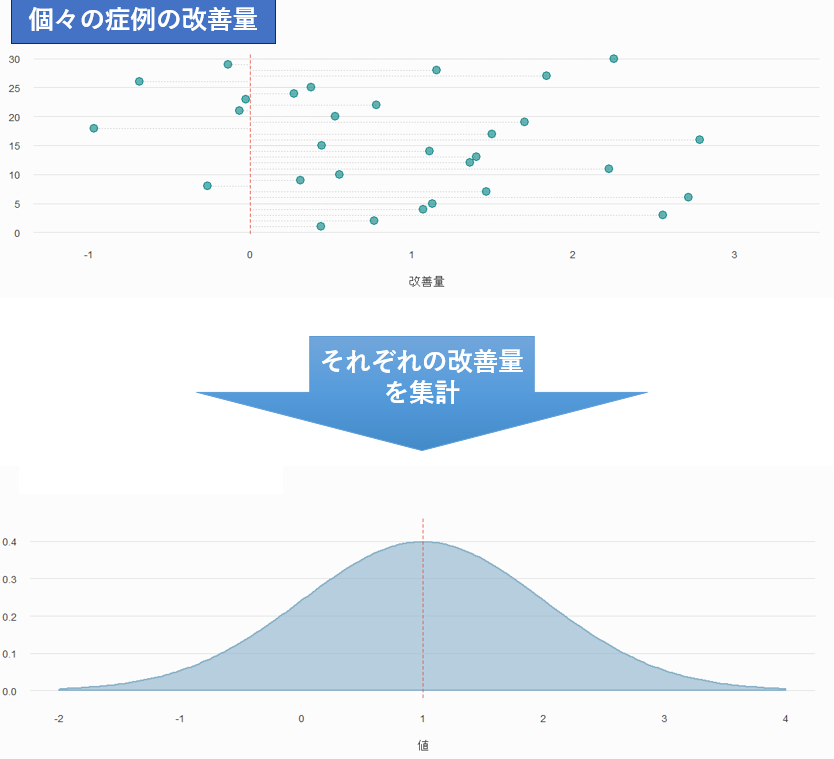
対応のあるt検定
2つの測定値(例:治療前・治療後のFIM)の差に注目します。この「差」が正規分布に従うことを前提にしています。グラフにするとこんな感じです。
対応のないt検定
2群(例:介入群・対照群)のそれぞれのデータが正規分布に従うことを前提にします。グラフでは、2つの釣り鐘型の重なり具合としてこのように視覚化できます。

回帰分析
連続したxの値ごとに、yの分布(残差)が正規分布に従うことを仮定します。イメージとしては、回帰直線に沿って小さな正規分布が並んでいる「金太郎あめ」のような構造です。3Dグラフとして視覚化するとこんな感じです。(マウスで動かせます。)
まとめ
この記事では、正規分布について次の内容を解説しました。
- 形を決めるのはμとσの2つだけ:位置と広がりで分布が完全に決まる
- 68–95–99.7則:SDの倍数で割合がわかる実用的な法則
- 標準正規分布とz変換:異なる分布を統一して扱うための変換
- 非正規データへの対処:対数変換、GLM、GLMMなどの選択肢
- 中心極限定理との関係:データが正規分布でなくても分析できる条件
正規分布は「統計の万能選手」と言えるものですが、実際には苦手なデータもあります。データの特性を理解し、正規分布を仮定してよい場面とそうでない場面を見極めることが、適切な統計解析への第一歩です。
この記事の内容に関するご質問・統計解析のご相談はこちらからどうぞ。
正規分布に関連のある記事
効果量とは?
95%信頼区間とは?
標準偏差とは?
標準誤差とは?

【著者について】
理学療法士(回復期リハビリ病棟 12年以上)
統計検定2級・Python 3エンジニア認定(データ分析)取得。
臨床現場でのデータ活用を目的に統計・機械学習を独学。
FIM退院予測モデルを個人で設計・実装(スタッキングアンサンブル+SHAP)。
強化学習(MuJoCo/Walker2d)や高位頸髄損傷患者向けデバイスの
自作など、臨床課題を技術で解くことに関心を持つ。
医療職向けに統計・データサイエンスをわかりやすく解説するブログ
「Curiosity Creates」を運営中。


コメント