

はじめに
時系列データ分析、特にARIMAなどのモデルを使った予測を行う場合、分析の大前提となる条件があります。それが「定常性(Stationarity)」です。
定常なデータとは、平均・分散・自己相関といった統計的な性質が時間によって変化しないデータのことです。右肩上がりのトレンドがあったり、時間とともに振れ幅が大きくなっていくようなデータは「非定常」であり、そのままARIMAモデルに投入しても正しい結果が得られません。予測モデルを作る前に、まずこの定常性を確認するステップが必要になります。
そこで使用されるのが単位根検定と呼ばれる統計手法です。
一般的にはADF(Augmented Dickey-Fuller)検定・KPSS(Kwiatkowski-Philips-Schmidt-Shin)検定が使用されます。
今回は、無料で使える統計ソフトJASPを使ってADF検定・KPSS検定を行い、必要に応じてデータを変換する手順を紹介します。
この記事では、最初に動画でADF・KPSS検定のデモを確認できるようにしています。そのあとに、検定の意味やJASPの実際の操作方法について紹介する構成になっています。
なお、定常性についてもう少し詳しく知りたい、という方はこちらの記事で紹介しています。
まずは動画でADF・KPSS検定の雰囲気をつかむ
実際の操作の流れを動画にまとめました。まずはこちらをご覧ください。
このように無料の統計ソフトであるJASPを利用すると、簡単に定常性の検定が行えます。
定常性の検定:ADF検定とKPSS検定
JASPでは、代表的な定常性の検定としてADF検定とKPSS検定を利用できます。この2つは、一見似ているようで、帰無仮説が正反対になっているのが重要なポイントです。
| 項目 | ADF検定 | KPSS検定 |
| 帰無仮説(検定の仮説) | 非定常である(単位根あり) | 定常である |
| p< 0.05の時の結論は? | データは定常 | データは定常ではない |
帰無仮説が真逆なので、判断の方向も逆になります。ADF検定は「非定常だと言えるか?」を問い、KPSS検定は「定常だと言えるか?」を問う、と整理しておくとわかりやすいでしょう。
なお、ADF検定にはひとつ注意点があります。サンプルサイズが少ないと、本当は定常なデータでも「非定常」という結果が出やすい(検出力が低い)という性質があります。両方を組み合わせて判断するのがコツです。
2つの検定を組み合わせると、結果は以下の4パターンに分類できます。
| ADF検定 | KPSS検定 | 判断 |
|---|---|---|
| p < 0.05(定常) | p > 0.05(定常) | ✅ 定常と判断してよい |
| p ≥ 0.05(非定常) | p ≤ 0.05(非定常) | ❌ 非定常。変換が必要 |
| p < 0.05(定常) | p ≤ 0.05(非定常) | ⚠️ 結果が割れている。トレンド定常の可能性あり※ |
| p ≥ 0.05(非定常) | p > 0.05(定常) | ⚠️ 結果が割れている。サンプルサイズ不足の可能性あり※ |
※結果が割れた場合はグラフを目視で確認しながら総合的に判断してください。
実際に検定をかける時の流れ
定常性の確認は、以下の順で進めます。
① グラフで目視確認
まずデータをプロットして眺めます。右肩上がり・下がりのトレンドはないか(単位根の有無)、時間とともに振幅が大きくなっていないか、周期的なパターンはないか、という点を確認します。これらが見られる場合は非定常の可能性が高いです。
② 統計的検定で確認
ADF検定・KPSS検定を行い、数学的にデータを処理します。
③ 非定常であれば変換して再検定
グラフの形状を参考にしながら、適切な変換を行います。変換後は再び検定を行い、定常性が確認できたら次のステップへ進みます。
【コラム】「単位根」って何?
ADF検定の正式名称は「単位根検定」といいます。単位根があるデータは、一度ショック(急騰や急落)が起きると元の水準に戻らず、フラフラとどこかへ漂っていってしまいます。この「フラフラとどこかへ行く性質」が非定常の正体で、ARIMAモデルが正しく機能しない原因になります。
データが定常でなかったら?:加速度的に増加するデータの場合
動画で使用したデータのように、加速度的に増加するデータには、以下の2段階の変換が有効です。
Box-Cox変換で分散を安定させる
時間とともに振れ幅が拡大している場合は、Box-Cox変換(または対数変換)で分散を一定に近づけます。JASPでは「Auto」があるため最適な変換係数(λ)を自動計算してくれます。
差分(階差)でトレンドを除去する
トレンドが残っている場合は、差分(Difference)をとります。差分とは「今日の値 - 昨日の値」に変換する操作です。マニュアル設定も可能ですが、たいていの場合デフォルト設定でうまくいきます。
下の画像をご覧ください。差分データは1時点前のデータと現在のデータの差になっています。そのため、「1時点前のデータ」が存在しない1行目は差分データが空欄になっています。これは差分処理の仕様で、必ず発生します。この空欄がエラーの原因となるため、後の手順(ステップ4)で対処が必要になります。

JASPでの操作手順
ステップ1:データの準備・分析メニューの準備
JASPではエクセルファイル(.xlsx、.xls)やCSVファイルが扱えます。
以下のようにデータを1列に並べたものを準備します。
なお、先頭行には列名を記載できますが、日本語入力だとエラーの原因となることがあります。半角英数で列名を入力しましょう。
データが準備できたらJASPを起動して、解析したいファイルを開きます。
次は時系列データ分析オプションをオンにします。
JASPはデフォルトだと時系列分析のメニューが表示されていません。下の画像のように画面右上の「+」マークから時系列分析メニューを有効にします。
JASPが問題なく動けば、上の分析メニュー欄に「Time Series」が追加されます。
次に分析メニューを開きます。
JASPでデータを開き、[Time Series] → [Stationarity] を選択します。
メニューをクリックすると、定常性の分析メニューが開きます。
分析したいデータを左枠から右側のVariable枠へ移動しましょう。
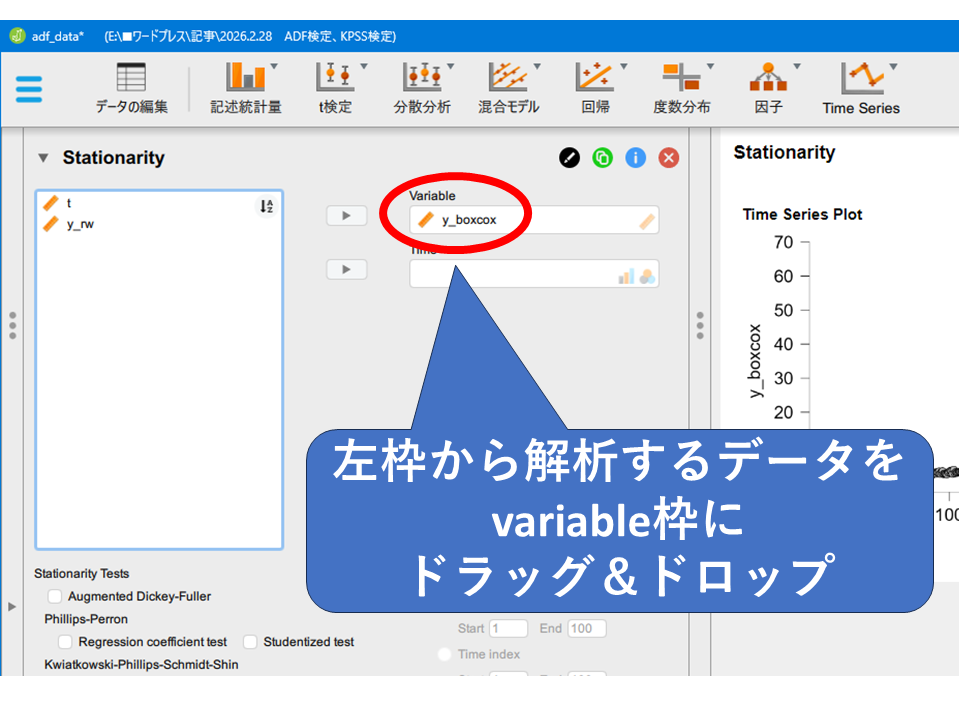
データを枠内に移動するとすぐに計算処理が始まります。計算が終わると右側の出力エリアにグラフが表示されます。データ量が多い(データが数千行など)と時間がかかることがあるかもしれません。
ステップ2:定常性検定を実行する
ADF(Augmented Dickey-Fuller)検定・KPSS(Kwiatkowski-Philips-Schmidt-Shin)検定にチェックを入れて結果を確認します。
KPSS検定にはチェックボックスが二つあります。Trend stationaryはデータにトレンドがある場合に使います。迷ったらTrend stationaryも合わせて確認しておくのが無難です。
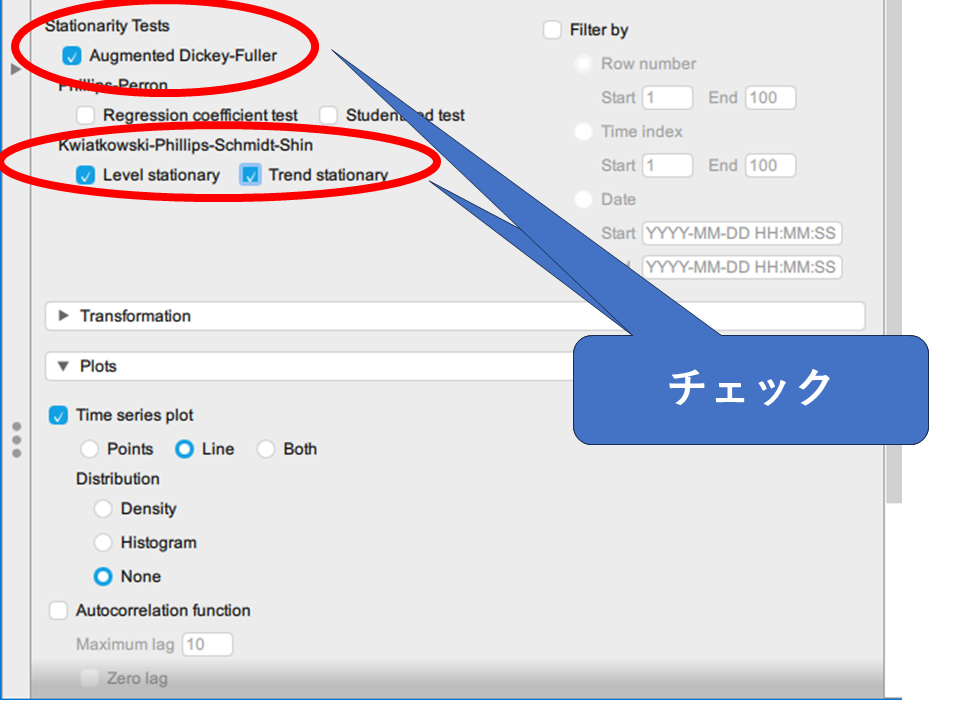
チェックを入れるとすぐに計算処理が始まり、ウィンドウ右側の出力エリアに結果が表示されます。
データが定常だと判断するには以下のような結果であることが必要です。
- ADF検定でp < 0.05
- KPSS検定で p > 0.05
結果を見てみましょう。
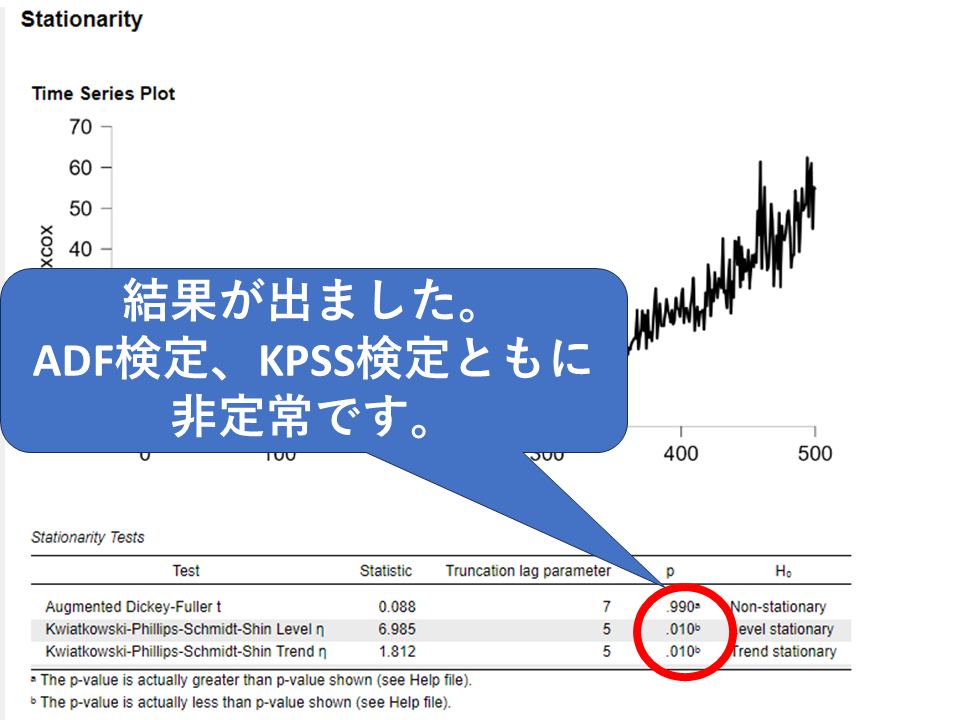
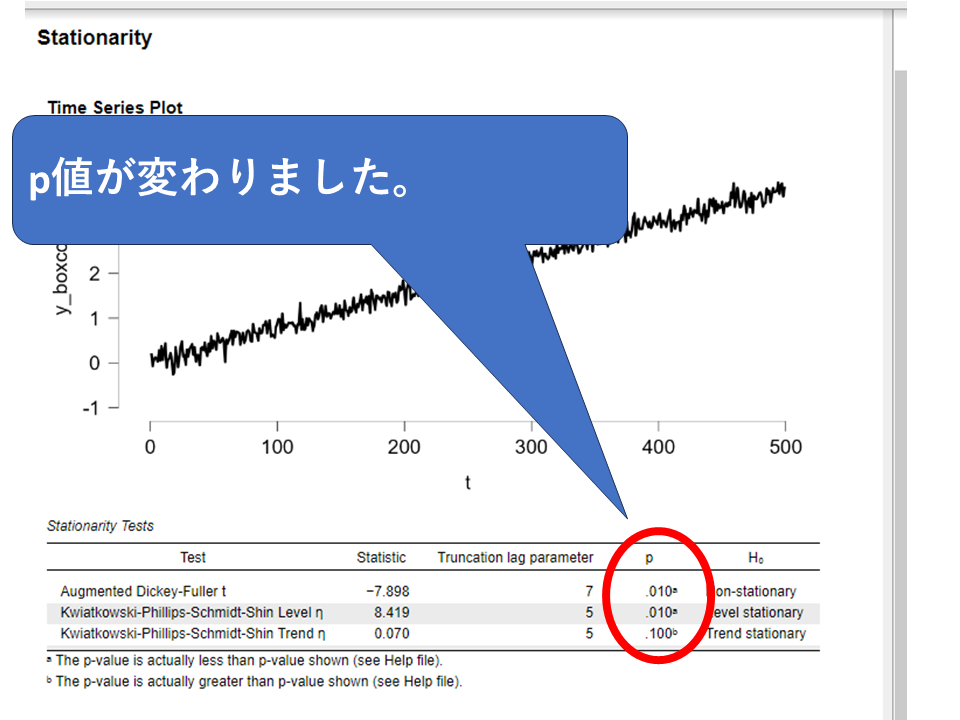
ADF検定はp = 0.990で帰無仮説を棄却できず(非定常の可能性を排除できない)、KPSS検定はp = 0.010で帰無仮説(定常)を棄却した、という結果でした。
つまり、データは定常ではないという解釈になります。
ステップ3:変換を行いデータを定常にする
データが定常ではなかったため、データの変換を行います。
[Transformation] メニューでまずBox-Cox変換にチェックを入れます。
チェックを入れると、出力エリアの検定結果がリアルタイムに更新されます。変換後はADF・KPSS検定の結果が定常を支持するものになっているか確認します。
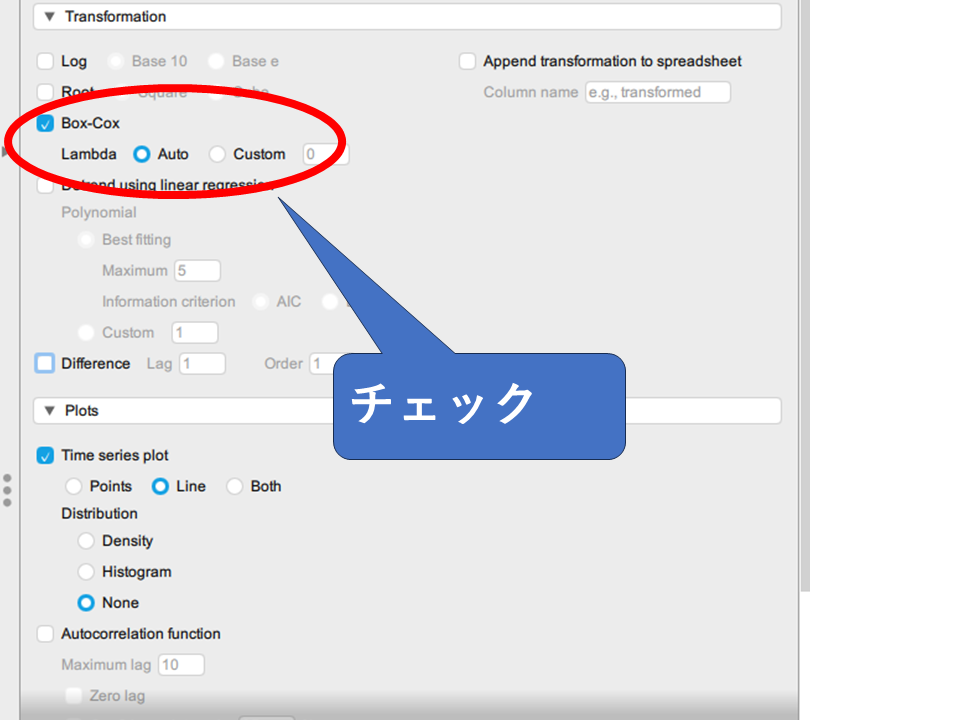
結果を見るとADF検定・KPSS検定(trend)の結果はデータが定常であることを支持する結果となっています。
グラフを見てもわかる通り明らかにトレンドが残っているため、KPSS検定(level)は非定常という判定になっています。
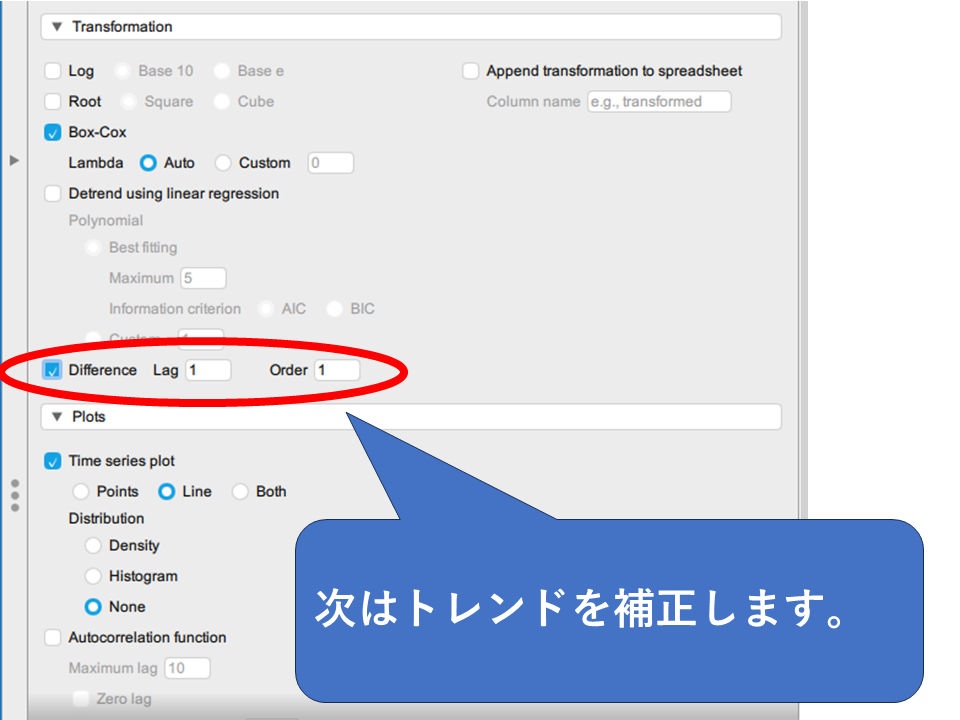
[Transformation]メニューでDifferenceにチェックを入れてトレンドを補正します。
なお、LagとOrderの欄は特別な事情がなければ初期設定で問題ない場合が多いです。
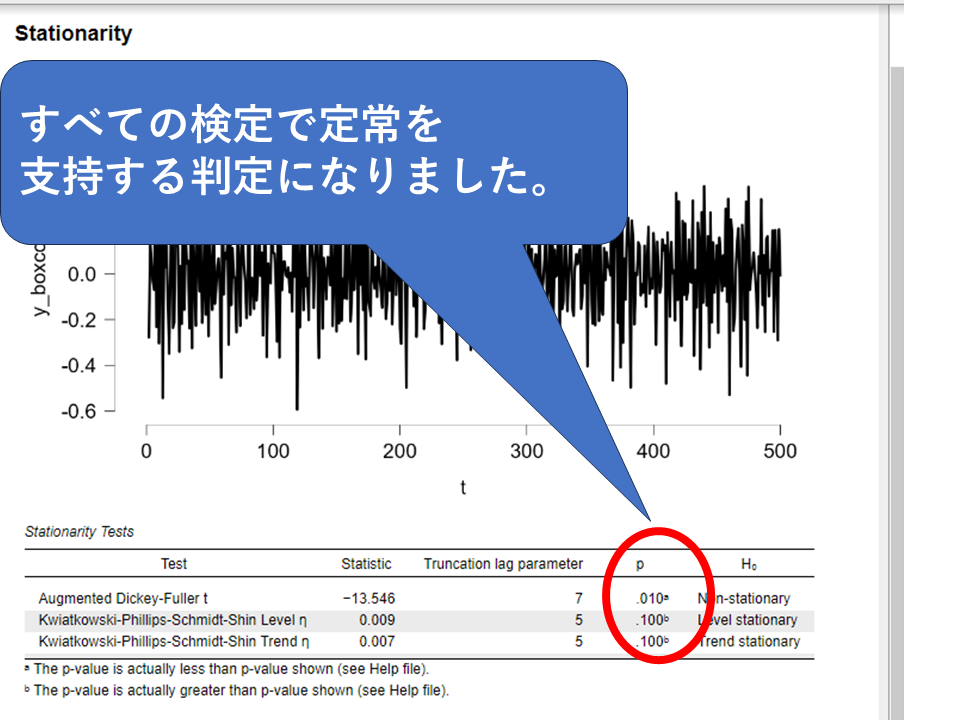
再度検定の結果を確認します。すべての検定でデータが定常であることを確認できました。
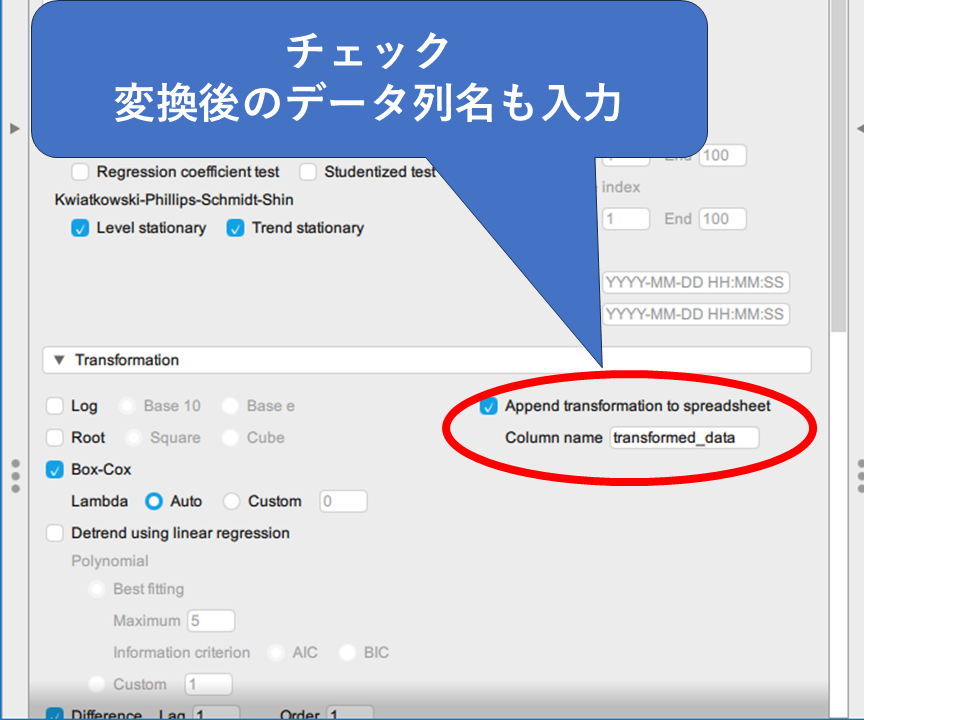
データが定常になったため、ARIMAモデルで分析できるように変換後のデータを新しいデータ列として追加します。
[Transformation]メニューから Append transformation to spreadsheetにチェックを入れましょう。Column name にデータ名を入力します。
なお、この操作では最初に読み込んだCSVファイルやエクセルのシートには保存されません。データの外部出力のためには別な操作が必要です。
ステップ4: ARIMAへ進みフィルタを設定して分析可能にする
[Time Series] → [ARIMA] へ進みます。
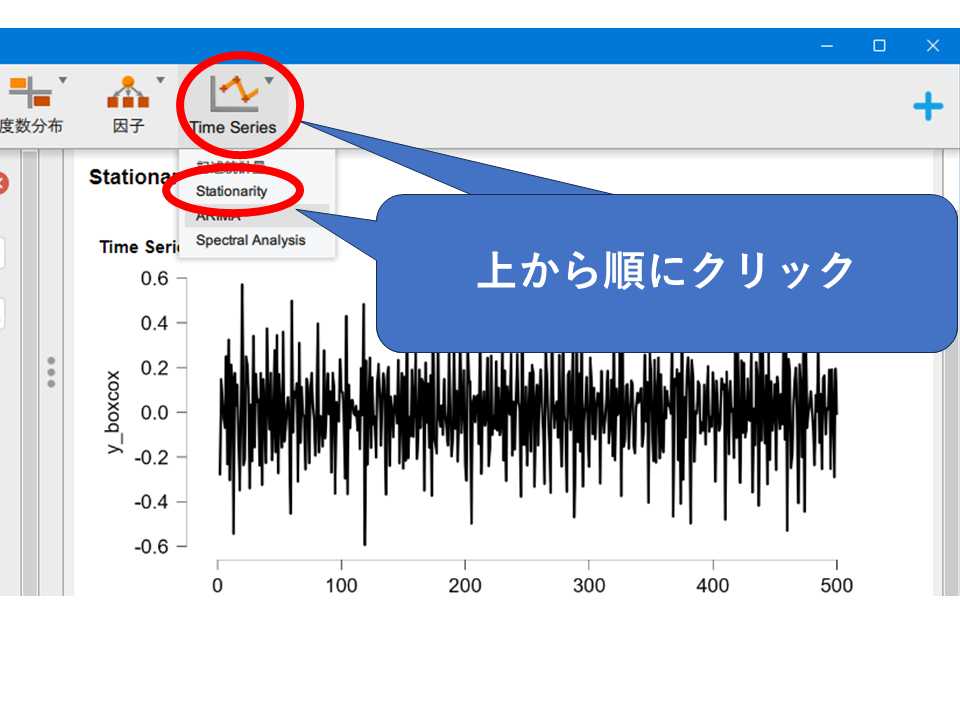
Transformed_dataを右側のDependent Variable 枠にドラッグ&ドロップします。
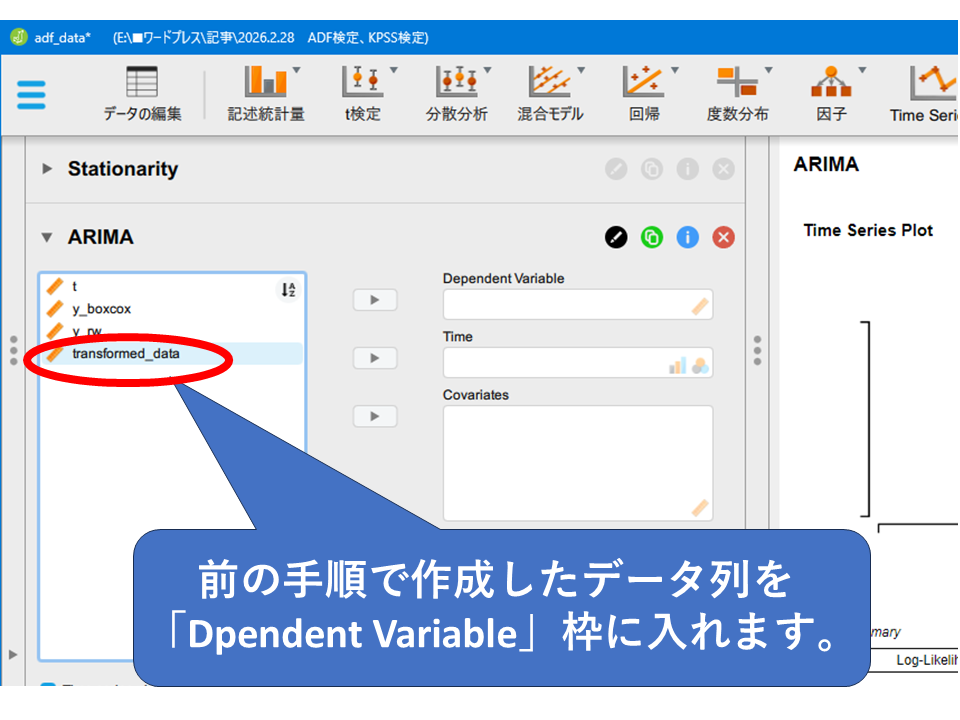
エラーが出ました。
このエラーは先ほどご紹介した、差分処理による先頭行の空白のために生じます。
「差分(階差)でトレンドを除去する」(該当部分にジャンプ)
ウィンドウ左上の「データの編集」メニューでも1行目が空欄になっているのが確認できます。
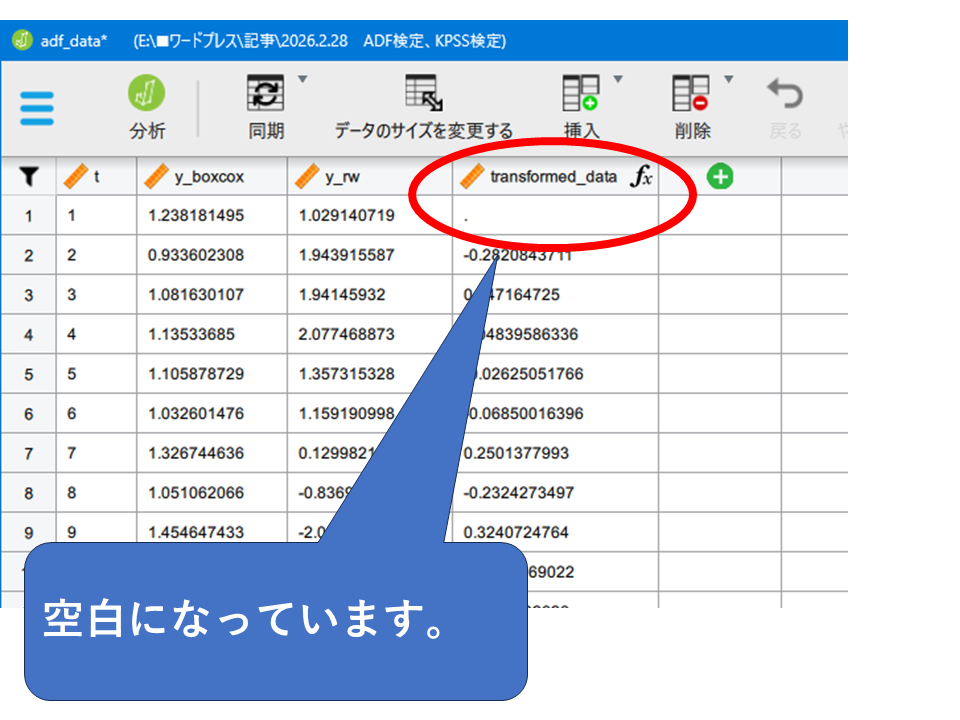
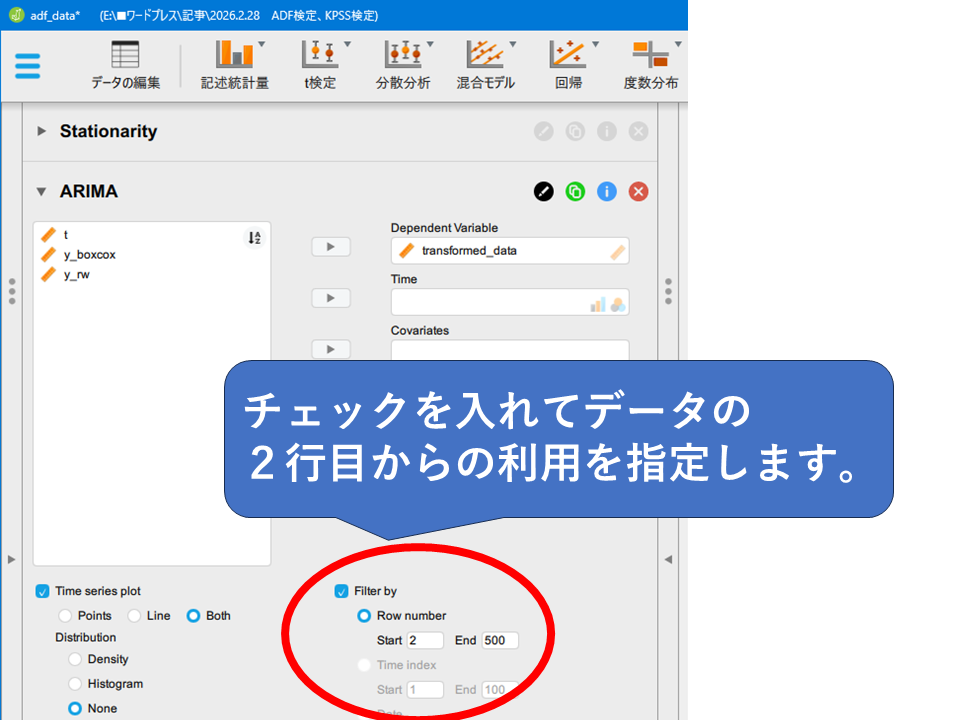
ARIMAモデルのメニューで分析に利用するデータの行数を指定することが出来ます。Filter byの部分で2行目からの分析を指定しましょう。Start とEndの欄に数値を入れることで何行目を利用するか指定できます。
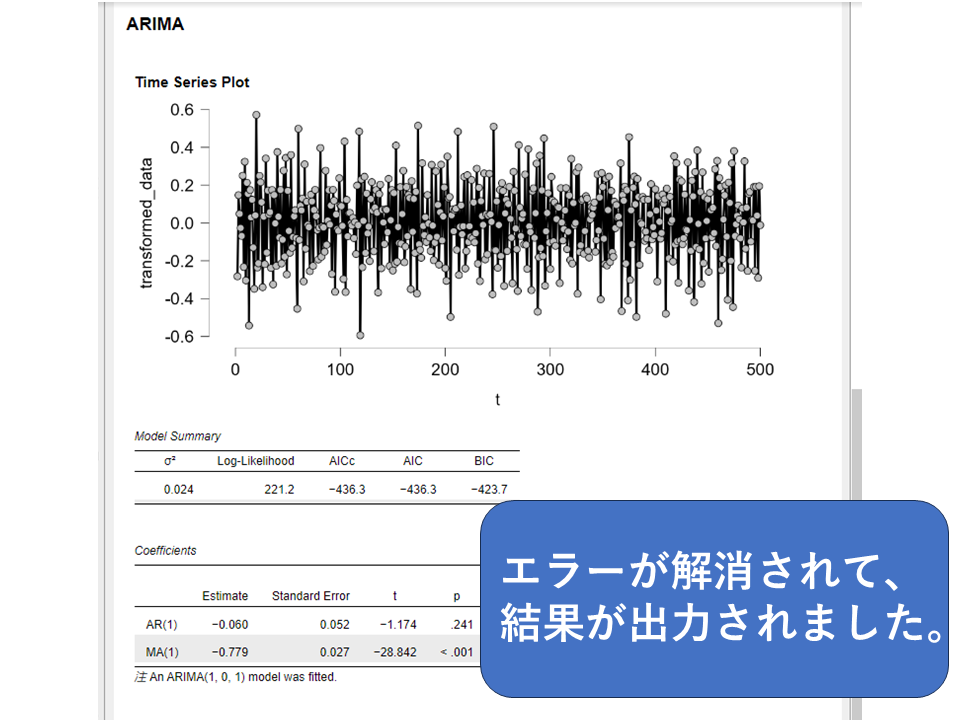
エラーが解消されて分析が実行されました。
まとめ
時系列分析の定常性確認は、グラフ確認 → ADF/KPSS検定 → 変換 → 再検定、というサイクルで進めます。
時系列分析における定常性の確認で、注意すべきポイントは以下の3つです。
- ADF検定とKPSS検定は帰無仮説が逆になっている。うっかり間違わないように注意。
- データによっては二つの検定の結論がきれいに一致しないこともある。その場合はサンプル数やグラフなどを見て総合的に判断する。
- トレンド除去のために差分をとると1行目に空白ができて、ARIMAモデルなどでエラーが出る。エラー回避のために、使用するデータの指定が必要。
JASPなら変換にチェックを入れるだけで結果がリアルタイムに更新されるため、試行錯誤しながら直感的に操作できます。ぜひ実際のデータで試してみてください。
本記事はJASP バージョン 0.95.4(2025/10/13 ビルド)を使用して作成しています。
ADF・KPSS検定に関係のある記事
医療データにも活かせる「時系列分析」とは?
はじめてのARMAモデル
SARIMAXモデルとは?
「定常性」をグラフで攻略!非定常の4パターンを徹底図解
【ADF・KPSS検定】マウスクリックで定常性を確認するやり方
JASPで時系列分析|プログラミング不要!ARIMA(SARIMAX)で未来予測

【著者について】
理学療法士(回復期リハビリ病棟 12年以上)
統計検定2級・Python 3エンジニア認定(データ分析)取得。
臨床現場でのデータ活用を目的に統計・機械学習を独学。
FIM退院予測モデルを個人で設計・実装(スタッキングアンサンブル+SHAP)。
強化学習(MuJoCo/Walker2d)や高位頸髄損傷患者向けデバイスの
自作など、臨床課題を技術で解くことに関心を持つ。
医療職向けに統計・データサイエンスをわかりやすく解説するブログ
「Curiosity Creates」を運営中。


コメント